Venue: Biomedicum 1, Meeting room B236a, 2nd floor
Hello Folks!
The coming Wednesday I will present you a show case of image analysis toolkit ANIMA running on Anduril.
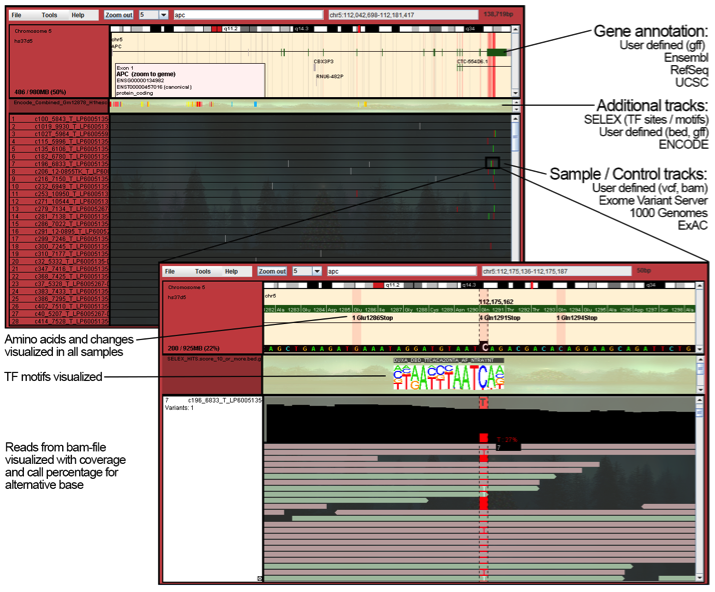
ANIMA is an image analysis workflow environment on top of Anduril an open source component-based workflow framework for scientific data analysis (developed in S.Hautaniemi lab). The Anima was used in visualizing and quantifying properties of 3D cell culture of kidney stem cells. In the presentation I’ll introduce key principles and questions of kidney development. Then I’ll pop the hood of ANIMA with the examples of how scripted image analysis answers question of the project.
WARNING: Lots of images, so you may want to bring popcorn!
NiceCSV is an interactive tabular data browser, as well as a text based tabular data formatter. The browser is capable of giving a quick overview of the data using a simple keyboard interface. The user may view basic statistics, sort by column, format the values, change alignment, or search with a keyword.
NiceCSV works in unison with other Unix tools, such as grep, cut and sed, reusing their capabilities for tabular data processing.
NiceCSV is freely downloadable and the source code is available at https://bitbucket.org/MoonQ/ncsv
It has no dependencies other than the standard Python libraries. The program is fully portable to all operating systems that run Python. (Cygwin required for Windows for the interactive browser)