
The Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial) celebrated its tenth edition in 2023 with a record number of submissions. Various members of the Helsinki-NLP group have contributed to this success, most notably Jörg Tiedemann as a co-founder of the workshop series, and Yves Scherrer and Tommi Jauhiainen as current main organizers. This year, three research papers were co-authored by researchers from Helsinki (Olli Kuparinen, Aleksandra Miletic, Janine Siewert, Yves Scherrer). Tommi and Yves also contributed to the three shared tasks proposed in the evaluation campaign this year. After two fully online and one hybrid edition, the 2023 edition was characterized by a growing on-site participation, with about two thirds of talks and posters presented in person.
One of the highlights of VarDial was the panel discussion (initially called “round table”, but we were assigned a fairly small room without tables, let alone round ones) that reflected on the past of VarDial and its future in the era of large language models. Our experts (Antonis Anastasopoulos, Gabriel Bernier-Colborne, Preslav Nakov, Tanja Samardzic, Ivan Vulic) agreed that even though the methods changed drastically over the last ten years, the VarDial themes were more relevant than ever. VarDial has also been known for its evaluation campaign primarily focusing on “hard” language identification problems such as those between closely related language varieties. The panelists were happy to see the continued interest in this campaign, but also wished for more varied downstream tasks to be included in the evaluation campaign. As organizers, we have always been strived to propose a wide variety of tasks, but struggled to attract sufficient numbers of participants. Furthermore, it was highlighted that dialects are first and foremost spoken varieties and that we should therefore focus more on spoken data in the future. The panelists viewed the ongoing consolidation of methods and the dominance of Transformer-based paradigms as a potential silver bullet that would hopefully make it easier for everybody to participate in future shared tasks.


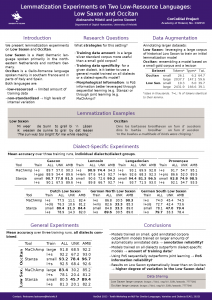
This year Slavic NLP (formerly Balto-Slavic NLP) included two papers from the members of our unit (Roman Yangarber and Anna Dmitrieva) who also contributed to the organization of the workshop and the shared task. The Slav-NER shared task is a multilingual named entity recognition challenge for Czech, Polish, and Russian, which also includes name normalization and entity linking. The top system’s performance on NER and normalization this year reached an F1 score of 90. Entity linking, a more challenging task, had an F1 score of 72-80, while cross-lingual entity linking had an F1 score of ~67, which is a great improvement compared to the previous challenge. The workshop’s best paper, “Resources and Few-shot Learners for In-context Learning in Slavic Languages” (Štefánik et al.), also touched on Polish, Czech, and Russian NER. The authors created an evaluation benchmark for in-context learning for these languages, supported tasks being NER, Classification, QA, and NLI.

