A couple of months ago, I had the amazing opportunity to come to the University of Helsinki as a visiting researcher. This was part of my PhD journey to familiarise myself with machine learning some more. As a forensic linguist, we’re often focussing our work on less automated ways of analysis, so I wanted to explore how I can make use of (semi-)automated processes in the forensic context.
A couple of months ago, I had the amazing opportunity to come to the University of Helsinki as a visiting researcher. This was part of my PhD journey to familiarise myself with machine learning some more. As a forensic linguist, we’re often focussing our work on less automated ways of analysis, so I wanted to explore how I can make use of (semi-)automated processes in the forensic context.
Since my PhD is exploring regional linguistic variation and its usefulness in authorship profiling, I wanted to work with someone who focuses their work in language technology on regional varieties. That is why I got in touch with Yves Scherrer and the Corpus-Based Computational Dialectology (CorCoDial) research group. Having read many of the publications coming out of VarDial, learning from and working with people active in this community was an excellent fit for me
 In total, I spent three months in Helsinki, from the end of February to the end of May. This meant that I could join some of the modules being held during that time, which allowed me to learn even more than just through collaboration. Additionally, I was able to join the research seminars held by the Language Technology research group, which meant I had an easy contact point to meet other researchers, but also to introduce my work to the group. Generally, the work culture is excellent and the joint lunch breaks make it easy to get to know people.
In total, I spent three months in Helsinki, from the end of February to the end of May. This meant that I could join some of the modules being held during that time, which allowed me to learn even more than just through collaboration. Additionally, I was able to join the research seminars held by the Language Technology research group, which meant I had an easy contact point to meet other researchers, but also to introduce my work to the group. Generally, the work culture is excellent and the joint lunch breaks make it easy to get to know people.
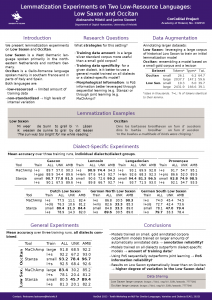
 The main focus of my visit was on a project within the CorCoDial group. We replicated a study which had come out only a couple of weeks before I arrived. In our experiments, we concentrated on extracting dialect features used by dialect classifiers. This was to evaluate whether dialect classifiers can be explained or interpreted, since, in forensic linguistics, one of the big problems with automated processes is that they are opaque and can’t be used in evidential contexts. We have submitted and presented our work at several conferences, for instance ICLaVE12, and were able to publish a preprint of our work (soon to be published in the NLPAICS proceedings).
The main focus of my visit was on a project within the CorCoDial group. We replicated a study which had come out only a couple of weeks before I arrived. In our experiments, we concentrated on extracting dialect features used by dialect classifiers. This was to evaluate whether dialect classifiers can be explained or interpreted, since, in forensic linguistics, one of the big problems with automated processes is that they are opaque and can’t be used in evidential contexts. We have submitted and presented our work at several conferences, for instance ICLaVE12, and were able to publish a preprint of our work (soon to be published in the NLPAICS proceedings).

Although I had some goals in mind for my time in Helsinki, this visit has exceeded them by far. I have learnt a great deal for my PhD, but I also acquired skills I will be able to use beyond the PhD. I have met outstanding researchers and was welcomed with genuine warmth and enthusiasm. I remain grateful that this visit was possible and I had this opportunity, but most of all I am thankful for the friends I have made and collaborations built for the future.



 Why coming to Helsinki?
Why coming to Helsinki?





 Another
Another 
 The language technology group from Helsinki has substantial presence at
The language technology group from Helsinki has substantial presence at  Our doctoral student, Anna Dmitrieva, has been highlighted
Our doctoral student, Anna Dmitrieva, has been highlighted  My name is Joseph Attieh, and I’m thrilled to introduce myself as the newest member joining the Language Technology research group led by Prof. Jörg Tiedemann. As I embark on my PhD journey, my primary focus will be on Green NLP, particularly in the areas of knowledge distillation and modularization.
My name is Joseph Attieh, and I’m thrilled to introduce myself as the newest member joining the Language Technology research group led by Prof. Jörg Tiedemann. As I embark on my PhD journey, my primary focus will be on Green NLP, particularly in the areas of knowledge distillation and modularization.