Jatkoa 16.5.2019 olleeseen sanomalehtisymposiumin osaan 1.
Sessio 2
Digitoidut sanomalehdet feminismin historian tutkimuksessa Heidi Kurvinen (Turun yliopisto) osoitti sen kuinka lehdet, omalta osaltaan, näyttävät kirjonsa, milloin ilmiö saa “nimen” ja milloin käsite alkaa saada lisämerkityksiä , ja milloin positiivisia ja milloin negatiivisia. Pohdittavaksi jäi, kuinka voisimme auttaa tutkimusympäristön luomisessa ja vinkata muista palveluista tai valmisohjelmistoista joilla pääsee jo pitkälle. DH-tutkijan ei (minusta) tarvitse välttämättä edes ohjelmoida, usein systemaattinen ja oikeiden työkalujen, oikea käyttö vie jo pitkälle. Se sitten, mikä on missäkin tilanteessa sopivin työkalu onkin sitten jo pidempi tarina.
Amerikansuomalaisten sanomalehtien ja ylipäätään sirtolaislehtien digitointia toivottiin. Aikakauslehdissä on jonkin verran, jotka löytyivät ikään kuin sattumalta, kun alettiin katsomaan lehtien ilmestymispaikkoja, mitäs ihmettä nämä New York – ilmestymispaikat ovatkaan?
Digitoitu sanomalehtiaineisto ja julkisen kuoleman käsittelyn tutkiminen Anna Huhtala (Tampereen yliopisto) . Tässä esityksessä lähestyttiin yhtä teemaa, jota aina välillä pohdimme sopimusneuvottelujen ja aineiston autenttisuuden parissa. Aineisto on aina aikakautensa näköinen. Toimitukselliset kriteerit ovat aikojen kulussa muuttuneet, ja journalistiset ohjeetkin on loppujen lopuksi luotu vasta 1950-luvulta, kun ensimmäiset etikettisäännöt lehtimiehille julkaistiin ja josta sitten hiljalleen kehittyi Julkisen sanan neuvosto ja journalistiset ohjeet. Murhenäytelmiä ja tragediaa… mutta toisaalta “millaisia teemoja valtavirralle tarjottiin lohdutukseen”, komentoi puhuja. Leikkeet olivat myös tässä tutkimuksessa oleellinen apuväline, joka auttoi tutkimusaineiston järjestelyssä.
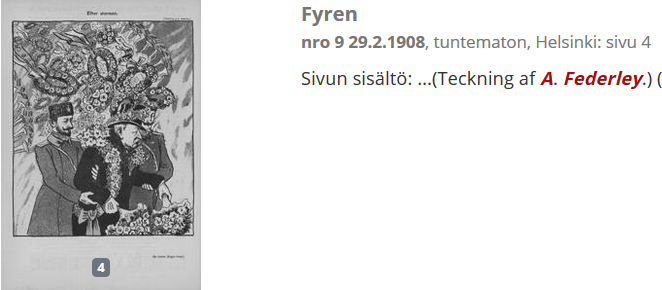
Pilapiirrosten tulkinta historiallisen diskurssin osana Meri Arni-Kauttu (Itä-Suomen yliopisto). Osittain palattiin jo ensimmäisissä sessioissa puhuttuihin stereotypioihin, mutta toisesta tulokulmasta. Olikin hieno kuinka esityksen kansikuvaa katsoikin tutkimusaiheen kuvauksen jälkeen aivan uusin silmin. Tosiaan, keiden näkökulmasta pilakuva olikaan tehty? Näyttää siis, että vaikka tekoäly ehkä “näkee” kuvituksen, niin silti kuvan ymmärtäminen ja kontekstin luominen onkin jo vaikeampi tapaus. Tutkimusta tarvitaan! Mainittiin esimerkiksi nimekkäät taiteilijat , kuten Alex Federley. Pikaisena digivinkkinä, nykyinen Digin “näytä kuvitukset”-toiminto pohjautuu sivun tekstiin ja digitoinnin jälkiprosessoinnin analyysiin suvasta. Haku tehdään sivun tekstiin pohjautuen, eli jos kuvan yhteydestä löytyy haluttu hakusana (esim. A. Federley) ja sivulta löytyy kuva, niin tällöin se näytetään haussa. Epätarkkuutta aiheuttaa se, että emme voi olla varma mihin tekstiin sivulla kuvitushaku osuu – se voi olla parhaimmillaan kuvateksti, mutta sanomalehdissä jotakin aivan muuta. Digissä kokeiltava esimerkkihaku: kuvitus + kuvituksen tekijä hakulauseessa sivun sisältöön pohjautuen (vain aikauslehdet) . Muokkaa ja katso mitä löytyy!
Sessio 3
Puoluehistoria ja sanomalehtiaineisto Kati Katajisto (Helsingin yliopisto). Tässä tutkimuksessa tuli hyvin esille kuinka aineiston kanssa saa olla tarkkana, erityisesti jos hakusana on yleissana, jolloin koivu ei välttämättä ole nimi tai voi olla ihan vain tuttu puulajike, … Joten hakutuloksia kannattaa aina tarkastella kriittisesti, nouseeko tietyn hakusanan ilmentymät koska asia aidosti on lehdissä merkittävä, vai vaikka vain siksi, että jokin mainoskampanja on aikanaan käynnistynyt, jossa tietty sana sitten esiintyy. Täytyy tuntea tekstin tai aineiston ominaispiirteet ja miten eri hakutulokset siihen suhtautuvat.
Kunnanvaltuustojen perustaminen ja sen herättämä demokratiakeskustelu lehdistössä 1890-1917 Sami Suodenjoki (Tampereen yliopisto) . Tässä kunnanvaltuustotyössä yhtenä tuloksena oli kunnanvaltuustotietojen lisääminen suoraan myös Wikipediaan, jolloin niihin pystyttiin lisäämään myös lähdetiedot, mistä lehdestä tietyn kunnanvaltuuston perustaminen löytyikään. Yleisöstä kommentoitiin, että hyvä olisi hyödyntää ehkä myös WikiDataa, jolloin tiedoista saisi ehkä myös entistä rakenteisemman ja mahdollisuuden linkittää dataa paremmin keskenään. Wikidata olisi muutenkin tiettyjen asioiden kanssa hyödyllinen, joten asiaa pitää pitää vireillä muutenkin.
Mormonien vaiheet 1800-luvun suomalaislehdistön kuvaamana Kim Östman (Åbo Akademi) oli hiukan aiemmin tehty tutkimus, mutta silti kiinnostava ja nykyaikaankin sopiva. Kuinka uusi ilmiö Suomeen tulee, ja millaista keskustelua se aiheuttaa lehdistössä tai ympäröivässä yhteiskunnassa. Kiinnostava ajatus oli, että tulisiko muista uskontokuntien tulosta Suomeen vastaavanlainen keskustelu , ja ylipäätään milloin ja milloin yksittäisitä mielipiteistä tuleekin yhteinen julkinen mielipide, joka alkaa ruokkia itseään?
Sessio 4
16:00-16:15 Näkökulmia Fenno-Ugrican sanomalehtien tutkimuskäyttöön Niko Partanen (Kotimaisten kielten keskus) osoitti sen, että laajasta digitaalisesta tarjonnasta on hyötyä ja mitä etua on, kun sama teksti löytyy useampana käännöksenä aineistojen joukosta (Github). Tässä kohtaa symposiumissa jäätiin pohtimaan tekstintunnistusta ja siihen liittyviä työkaluja – oikeastaan tekstintunnistus ei ehkä enää olekaan se ongelma (ainakin malleja pystyy opettamaan ja työkalut kehittyneeet), mutta haaste voikin enemmän olla se, kuinka hailakka sivukuva saadaan segmentoitua niin, että tekstintunnistukselle tarjotaan sopiva alue, josta teksti saadaan luotettavasti ulos. Sanat, virkkeet, kuvatekstit, mainokset, ovat pulma, kun lehtien rakenne vaihtuu vuosikymmenittäin, ja opetusaineistonkin teko on hidasta, tai kuten Digitalia-projektissa on huomattu, eri lehdet voivat vaatia oman mallinsa. Ehkä voikin tehdä vain työtapamallin, jolla erilaisia lehtiä taklataan, ja jatkaa työtä lehti lehdeltä eteenpäin, mahdollista hyvän, avoimen lähdekoodin, segmentointityökalua odottaessa.
16:15-16:30 Digitaalisten aineistojen käyttö väitöskirjatutkimuksessa Inkerin kirkon nousu ja suomalaiset 1988-1993 Antti Luoma (Helsingin yliopisto) . Aineistojen valinnassa voi olla myös monipuolinen – erityisesti jos tutkimus vaatii tuoreampien aineisotojen käyttöä, tällöin tulee ilmi se, että koko lehti on digitoitu koko historialtaan vain muutaman lehden osalta ja tätä avattiinkin keskustelussa seminaarissa.
Ylipäätään tämä avasi tutkijan haasteita, aineistoa etsitään eri puolilta, hieman eri tavoin, ja näin saadaan luotua laajempi kuva tutkittavasta kohteesta yhdistämällä arkistomateriaalia, sanomalehtiä ja vaikka jopa TV-ohjelmia, jotka voivat osaltaan käynnistää keskustelun sanomalehdissä ja sitten taas ilmestyä arkistomateriaaliin tovin kuluttua. Yhtenä kiitoskohteena aiemmin mainittujen aineistojen lisäksi mainittiin Kavi:n Ritva-tietokannan kanssa oleellista on metadata, jolloin voi helposti löytää haluamastaan teemasta ohjelmia.
16:30-16:45 Painettujen ja käsinkirjoitettujen lehtien vertaileva tutkimus – digitoinnin tuomat uudet mahdollisuudet ja haasteet Kirsti Salmi-Niklander (Helsingin yliopisto). Takaisin paperiin! Kaikkea ei kuitenkaan ole digitoitu ja yksi esimerkki tästä on pienehköt teemalehdet, joita ei välttämättä ole julkaistu vaan jaettu rajatussa piirissä, kun tavoitteena on ollut esimerkiksi välttää sensuuria. Käsinkirjoitettujen lehtien löytämisessä on jo omat haasteensa, ja irtolehtien koostaminen on jo iso työ, kun metadatakin on luotava itse. Toivotaan, että NewsEye- tai Read-projektin eteneminen käsinkirjoitetun tekstin tunnistuksessa etenee nykyisellä vauhdilla, niin sitä voisi käsinkirjoitettuihin ainistoihin käyttää.
Summa Summarum
“Helppo tiedonhaku auttaa ymmärtämään omaa kulttuuria”
HS:n pääkirjoitus 21.5.2019.
Seminaarissa osallistujana yksi taustateema oli, että kuinka monipuolista ja kiinnostavaa tutkimusta eri yliopistoissa tehdään. Vaikka yhteistä ei ehkä ole kuin osa aineistoista, tai palvelu josta aineisto löytyy, osaan ideoista on löydettävissä ratkaisuja, jotka auttavat monia. Digi.kansalliskirjasto.fi -esitysjärjestelmän kehityksen yksi kantava ajatus onkin ollut, että lisättävät toiminnot olisivat yleishyödyllisiä – toimintoja, jotka toimivat sekä tutkijoille, että muille käyttäjille, jolloin yhdellä toiminnolla saadaan eri käyttäjäryhmät katetuksi edes osin, jolloin tie jää auki jatkaa siitä eteenpäin.
“Aineistot ovat työväline”
Symposiumin lopussa huokaistiin myös ylläoleva “Aineistot ovat työväline” , eivätkä itsetarkoitus. Kukin toki innostuu aineistosta tai työkalusta, jolla pääsee haluamaansa asiaa tekemään, mutta ytimenähän on tutkimuskysymys ja sen ratkaiseminen. Luonnollisesti digitaalisten aineistojen kehittäjänä (sekä sisältö eli digitointi että palvelun toiminnallisuuksien kannalta) , haaste on ennakoida tulevia toiveita – sisältötuotanto etenee omaa vauhtiaan projektien myötä, ja sen lomassa aineistojen rikastaminen päästää syvemmälle jo nyt tehtyjen digitointien suhteen – kuinka helpottaa hakua ja antaa uusia mahdollisuuksia saada kuvaa vaikka aineiston osakohteista, jotka voivat edelleen nostaa mahdollisuuksia uusien tutkimuskysymysten käsittelyyn. Esimerkiksi juuri julkaistussa tutkimusartikkelissa (Hiding in Plain Sight: Poetry in Newspapers and How to Approach it) siitä kuinka DHH17-hackathonissä tehtiin runojen etsintää sanomalehdistä verraten käsityötä ja koneoppimista, jossa huomattiin että molemmista menetelmissä on hyötynsä ja molempia voi hyödyntää samanaikaisestikin.
Eteenpäin
Toivottavasti sanomalehtisymposium järjestetään ensi vuonna uudestaan ja voimme laajentaa kestoa ja saada lisää osallistujia, jotka toimivat muidenkin aineistolähteiden parissa tai jos on aineistoja joihin toivoisi pääsevän käyttämään, mutta keinoa ei vielä ole löytynyt.
Tavoitteena on parantaa tutkijayhteistyötämme, jossa työmalleina onkin jo olleet tutkijoiden aamukahvit, dataklinikat eri yliopistoissa, osallistuminen ja esittäminen eri tutkimusyhteisöjen seminaareissa ja erilaiset julkaisut. Palautetta voi vakiotavoin jatkuvasti antaa, ja käytämme mielellämme hyviä ideoita palveluiden (teknisten tai tutkijapalvelujen ylipäätään) jatkokehityksessä. Esimerkiksi Digitalia-projektin tuotoksia alkaa hiljalleen Digi-palveluun ilmestyä, uutuuksista lisää myöhemmin tässä blogissa.