
As has already been in earlier years, the DHH19 hackathon was due. This time there were:
- 38 participants
- 10 days
- 4 teams and projects
- Computer science + social science + humanities
This time DHH19 went international, and the group was versatile
This year #dhh19 went international. pic.twitter.com/Id8BdWyFAD
— Mikko Tolonen (@mikko_tolonen) May 24, 2019
There was communication part in each team, which explained at least the Twitter-using teams, and there were also interviews made from the participants.
13:20-14:30 Group presentations
DHH19-Brexit group
RQ: What is the relationship between social media and politics?
- Types of tweets: retweet (massive amount), original, reply, quotes
- Checked regional tweets, and who are the most dominant users.
- 1 user can be responsible of certain combination of hashtags (whose account anyhow suspended)
- Real-life events vs events on Twitter
- Several hashtag groups can be identified and that was visualized and put to a timeline (as assumed that hashtag correlates to a time)
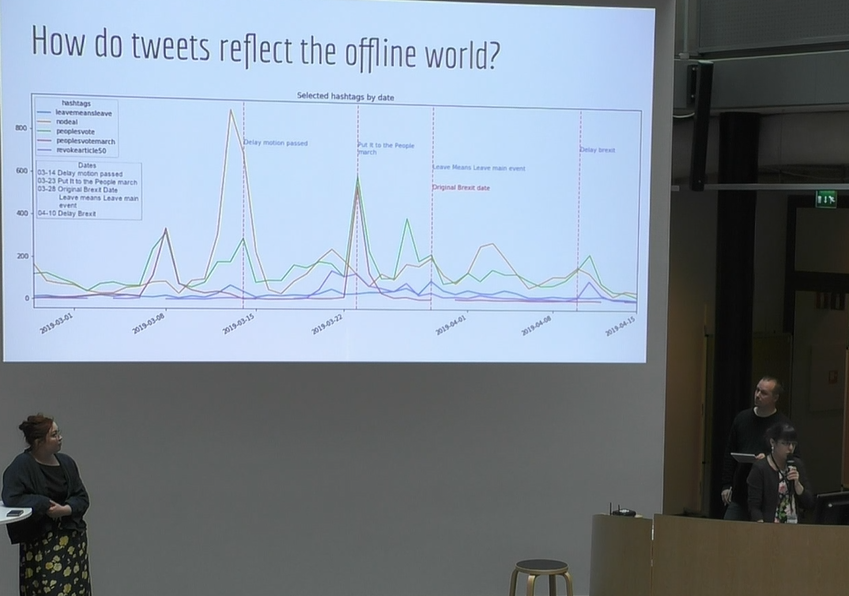
- Research on subgroups: all users, verified users, members of parliament
- Frequency analysis: most shared Twitter content vs. external content.
- Blame : groups mobilise different content to futher their agenda
- Who are people angry at? “the anger scale” (person id’s of angry tweets)
- hashtags of MP’s ; hashtag avoidance by politicians? (removal of themselves from the discussion?)
- Problems: how well the dataset matches the population, e.g. PM is missing from the data?
- Experimented with NER, ‘May’ ends up as Date 🙂
- tweet json contains so many fields, where rt’s and hashtags don’t get to correct field due to way how api was used
- https://blogs.helsinki.fi/digital-humanities-hackathon/brexit
- Couldn’t go further to data as historical data would have a cost of several thousands of euros.
The @dhh19_EP takes the stage #dhh19 pic.twitter.com/G5BKvVG2WO
— Mikko Tolonen (@mikko_tolonen) May 24, 2019
DHH19-EU Parliament group
- Update on communications
- “We communicated”
- the future, << political discourse & debate >>, history, the past
- What is EU?
- Whole corpus
- 249,955 speeches in English, 50M words, 2M sentences
- metadata: speaker (name, country, political functions, gender, date, topic)
- 2013 change in protocol, after 2013 , 99.7% of English speeches from UK and IRL
- Created subcorpora:
- picked keywords, to find suitable parts from data, brainstormed ideas for subset, observed data , topic modelling, word embedding… and selected keywords then
- word ‘past’ might work if they talk about last session
- Past: 13.230 speeches, future 5430 speeches, totaliariasmi 4517, climate change 12k
- Key results
- Past and future are very related
- Construction of Future (network with ‘key hubs’)
- Thinking conceptually what is the future
- Topic modelling : which topics connected with the past or to the future
- Sentiment analysis : speakers seem to be less emotional and more concrete while talking about future. (Utilized existing tools for doing analysis)

- variance of sentiment analysis
- analysis of sentiment analysis compared to gender, country -> by this noticed the 2013 issue
- Qualitative analysis: close reading to extract ideas between past and the future. MP’s utilize ‘past’ elements as something to avoid or sometimes as some things to preserve & generic human values.
‘Future’ is something to plan , fear or hope for
* RQ: Case study 20thcenttot” How is the horseshoe theory present in discourse on the topic and how does it differ by region (E/W)?
- strongly connected in discourse, with no significant differences between East and West
- frequency analysis of specific terms, 2005 a spike visible .
* RQ: Case study: The climate crisis. How is climate change talked about in EP? Are there differences how diff countries talk about it?
- Proportion of speeches in climate change, spike in 2007 to 2010 (combination of current events, 2008 – 2011 first impl of Kyoto protocol). Might be impacted by nbr of speeches
- Sentiment analysis – by country , a problem found. E.g. Lux vs. IRL , sth in the data (number of speeches vs. climate speeches)
- False positives and negatives in understanding the sentences.
- Compared Finland & Spain: word clouds differ , in Finlandd emission, carbon at top, in Spain: water , mediterranean
Challenges
- defining the past and the future: how to detect it in the corpus?
- Missing English translated speeches and missing metadata
- English corpus included other languages
More work to do: look at differences between political parties ; issues w dataset should be solved.
A break: coffee (&tea) consumption in DHH2019
15-16 Groups
DHH19-Genre and Style group
“Name-dropping in 18th century public discourse”
RQ: Which personal names are frequently mentioned in 18th century British publications? On the basis of the freq and co-occ. of individual names, what kind of patterns can we detect that are characteristic of genres and time periods?
Data:
- 18th century collections online (ECCO)
- high representativeness: ca 50% of all 18th century British printed texts (180k titles, 32M pages)
- OCR issues, unreliable metadata
Analysis
- Keyword analysis
- Three subset over time: hist, relig, social
- Methods

Results:
- “Even when data was good it was not standardized”
- Name dropping was used in text (Queen elisabeth, Cicero,…)
- Identified the most common people mentioned
- Looked at this over time (20-year periods)
- The people mentioned in books have some similarity context (network of books, clusters of religious texts, historical texts, social affairs where subclusters)
- Origins of mentioned individuals (ancient, classical, early medieval, late medieval, renaissance, contemporary, NA)
Future research:
- Automatic genre classification based on named entity networks
- Improve NER and subsets by using domain-specific resources
- examine less popular entities and their role
- focus on 1st editions, inspecting specific sections of books
- creating interactive visualizations
Communication: blogs medium & blogs.helsinki.fi, Twitter (1 post from everyone), Instagram.
DHH19 – Newspapers
Why newsppapers? “Most important public record from the past”
Research themes:
- presence of ads
- language of persuation
Approach
- working in smaller groups, 2 meetings every day. Interlinking blogs
Results
- Presence of ads in morning post 1800-1900
- everything compared to the ads quantity
- Åbo Underrättelser 1824-1890
- Only a handful of finnish Newspapers have ad segmentation , none in 1892-…
- The development of Ads in British Newspapers 1800-1900 : country, city and paper level
- The pres. of ads in Morning post 1800-1900

The language of persuasion in advertisements
- What linguistic strategies were used for persuading people into buying or using?
- close reading of 1 newspaper issue per decade
- Testimony : authority & ordinary people
- Advertisements used adjectives, describing the high quality of the product – compared ratio of ads vs. articles -> no differences
- Interesting was the ratio of words (ads vs. articles) (ads used short sentences, easy to remember)
3. “The pills that cure everything – drug advertisements” ( a subcorpus)
- compared gender
- found out which illnesses the ads were targeted against
- descriptive language compared between different ads, e.g. ‘nervous’ came less important in women ads, but not on males – treatment of the word maybe changed.
- illustrations with the ads were interesting between diff genres (very different contexts, emotions visible for e.g. nervousness)

3. job advertisements, class and societal change?
- most sought occupations in newspaper ads /HISCO categories
- requirements connected to different occupations
- social and cultural expectations regarding these jobs
- differences between country in terminology, and even industrial changes
- top 15 occupations in Åbo Underrättelser : e.g. teachers !
Problems
- OCR…
- article separation (british newspapers)
Plan for future research
- 10 days, couldn’t do everything they wanted
- typology, trajectories, rhetorical tropes, medical/drugs & hysteria, marketing strategies
Dashboards available online.
Summa summarum
Sounds like that the hackathon was very interesting and the teams got far. Tools were used in interesting ways. Need to be considered how the ideas here could be used in research and development work done in the Digitalia project, too. This gave good food for thought 🙂