On 22nd of April, MAMK organized a dataseminar about how data, AI and technology can increase well-being.
Keynote about emerging Watson technologies
Keynote by IBM’s Vince A. Daukas, went through the problem with current data amounts, the basics of the solution and how IBM’s Watson and the system of services can respond to different usage purposes. One of the present facts is that the amount of data increases all the time, and it was mentioned that
2.5B gigabytes of new data are generated every day. Appr 80% of data is unstructured.
IBM also sees that there is a new era of ‘cognitive computing‘ (some info also in Finnish). The idea is to simplify processing of mass amounts of data, e.g. via machine learning to reduce need for programming and make interactions more human-friendly.
IBM’s Watson system was also extensively gone through – it incorporates concepts of technology, platform, solution. From the examples given, it seemed that (nearly) every kind of data can be simplified, referenced and utilized by it more better. Like in the case of the National Library of Finland, reading of all of the 10 million digitized pages would take beyond 10 years, the Watson can capture all of the research article, patents, and what ever content is seen significant and create new connections. At the Q&A, this was also later opened bit futher – the data stays at the content server, but Watson ingests data all the time, to capture new ones, and if needed rankings and prioties can be tought.
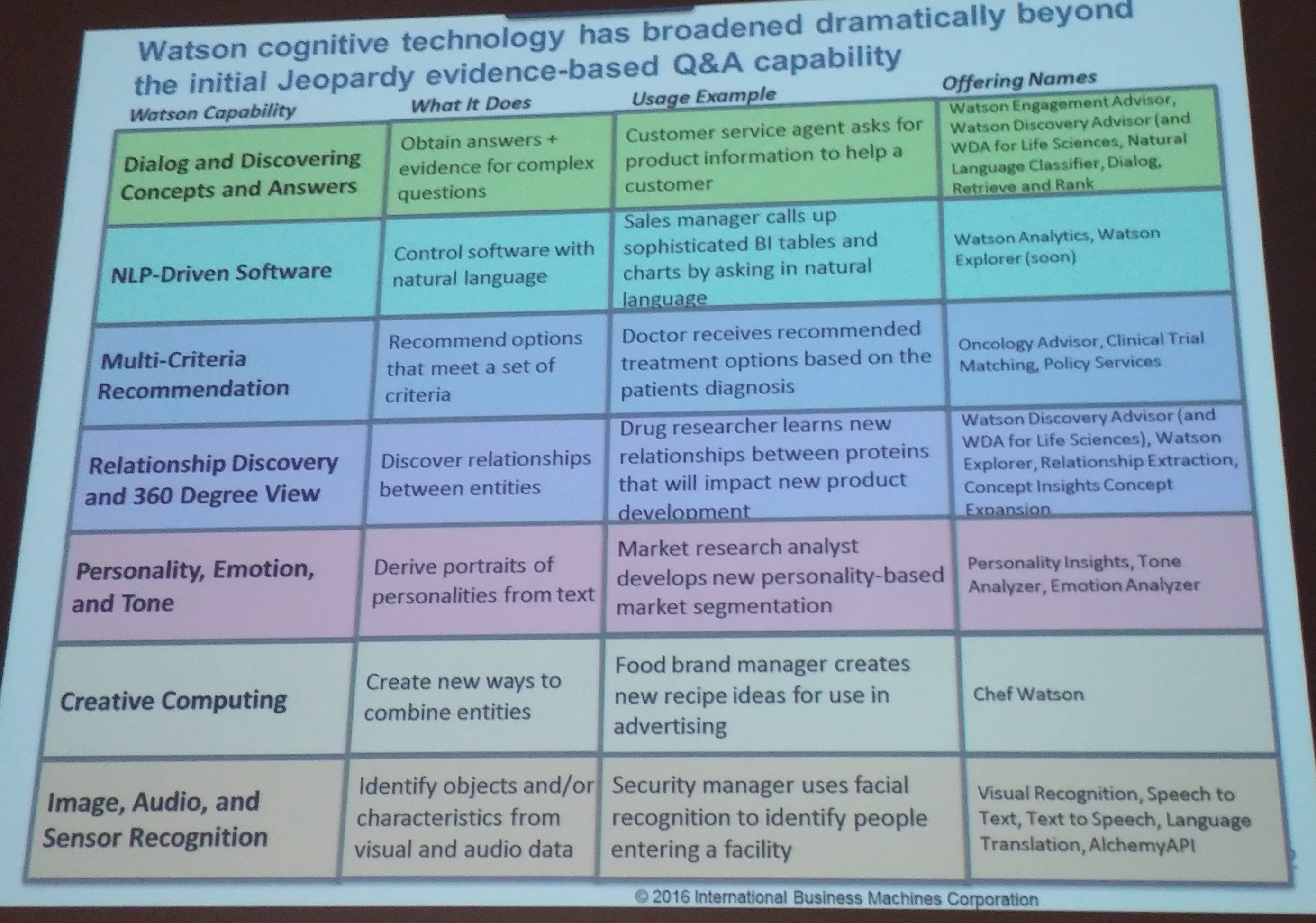
In a way, also AI technologies have the very familiar concerns, too. It is important to know what the technology can do, and how (and probably where) it can be applied. As it is a business, then it needs to be evaluated what is the ROI and high-value use cases, into which research or effort is put. Training routines for both people and machine requres thinking and the perceived risks with data privacy, cloud and AI need to be governed.
 Watson and health
Watson and health
Jukka Rupponen then went deeper with Watson from the angle of health- and wellness. He began by startling the audience with a (sad) fact:
$7.8 trillion is expended annually for health and social programs around the world. Up to 30% of all that money is wasted.
There was also consideration on division of labour as usual in the automation cases, namely that that humans, computers and cognitive systems should each focus to the area where they work best.
 The idea is that the app developer starts with their question and who then can use the many services offered, like IBM Watson Developer Cloud, Discover Advisor, which were mentioned as examples. For the developers the important links were given: https://console.ng.bluemix.net/ and http://github.com/watson-developer-cloud to get actually started with the services.
The idea is that the app developer starts with their question and who then can use the many services offered, like IBM Watson Developer Cloud, Discover Advisor, which were mentioned as examples. For the developers the important links were given: https://console.ng.bluemix.net/ and http://github.com/watson-developer-cloud to get actually started with the services.
Finnish examples – Disec & Kuopio
Health information gamification was talk from the Disec, who takes care of storing the medical images. Annually there comes around 700.000 new images and th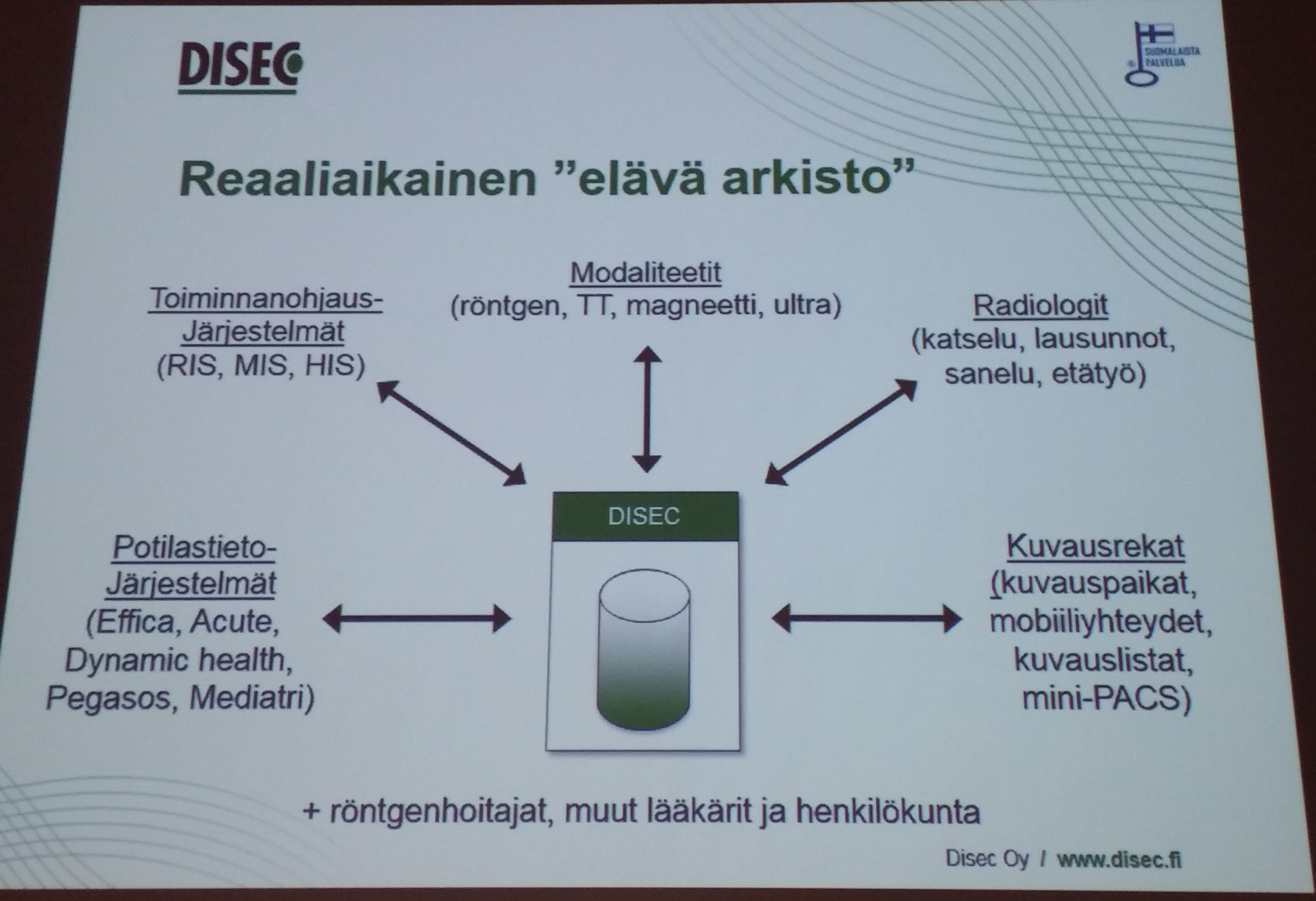 e storage time is at minimum 12 years. When we at library deal with standards like METS, ALTO, PAS, in the health side there is HL7, DICOM and on top of that all the health care systems, which either manage the workflow or are the multitude of tools to the doctors.
e storage time is at minimum 12 years. When we at library deal with standards like METS, ALTO, PAS, in the health side there is HL7, DICOM and on top of that all the health care systems, which either manage the workflow or are the multitude of tools to the doctors.
As an interesting contrast the speaker mentioned of a research from 2015 where pigeons were trained to observe anomalies from images. Apparently after a week they can detect minute changes like calcifications from mammogram images quite well. This caused some remarks as then the human, watson and pigeons were playfully compared to each other.
Kuopio Innovation talked about the gamification and healt h – the speaker saw that as real opportunity for Finland. The idea was to think from user in the center, and then via gamification find ways to activate, educate and overall find ways to improve life quality.
h – the speaker saw that as real opportunity for Finland. The idea was to think from user in the center, and then via gamification find ways to activate, educate and overall find ways to improve life quality.
The Q&A session was also quite lively, the audience had lots of subject matter experts, who were able to get also in the details based on lectures of the presenters. As said by the HackLab tweet:
Tämän seminaarin pohjalta on hyvä jatkaa huomiseen #hackathon‘iin! #futurehack #Mikkeli https://t.co/Mjzh1HWpWe
— Hacklab Mikkeli (@HacklabMikkeli) April 22, 2016
It sounded like that this hackathon is just a kick-off to longer-term work, so as discussed at the end of the event, the idea was to start from one small idea, and do what is possible in two days and continue later on. One idea can act as a wedge and build up to new things. The developers will surely be interested of all the building blocks and apis of IBM services provide.
P.S. The session was also covered by web article and local news (the TV clip link is valid until late May).