
Existing users of the http://digi.kansalliskirjasto.fi web service, might have noticed few new functions, which were launched at the end of last year. There already has existed an opportunity to copy a nifty reference to Wikipedia , but now we experimented bit to take it to next level with adding support for RefWorks. RefWorks is quite commonly used in e.g. University of Helsinki for managing references of all kinds.
If this sounds like useful or even fun, then follow these instructions.
- Firstly, find the page or clipping, which contains the information you want to cite
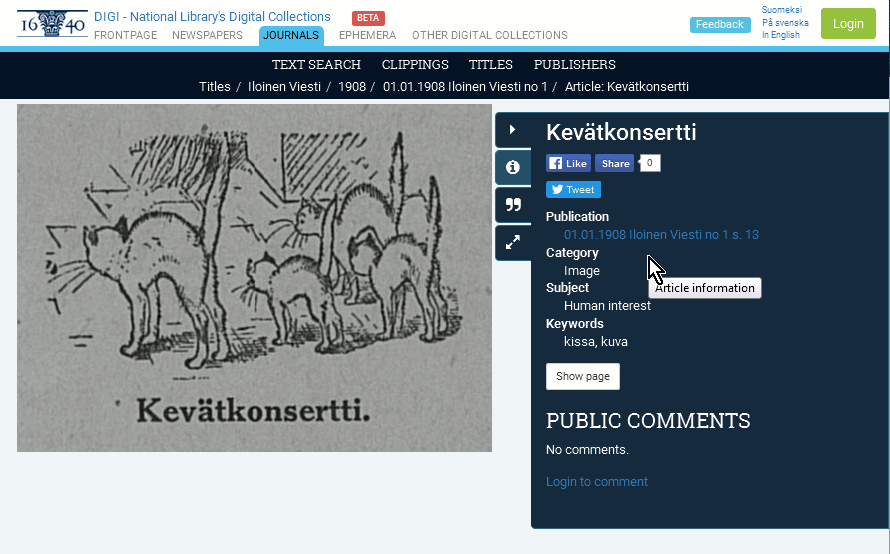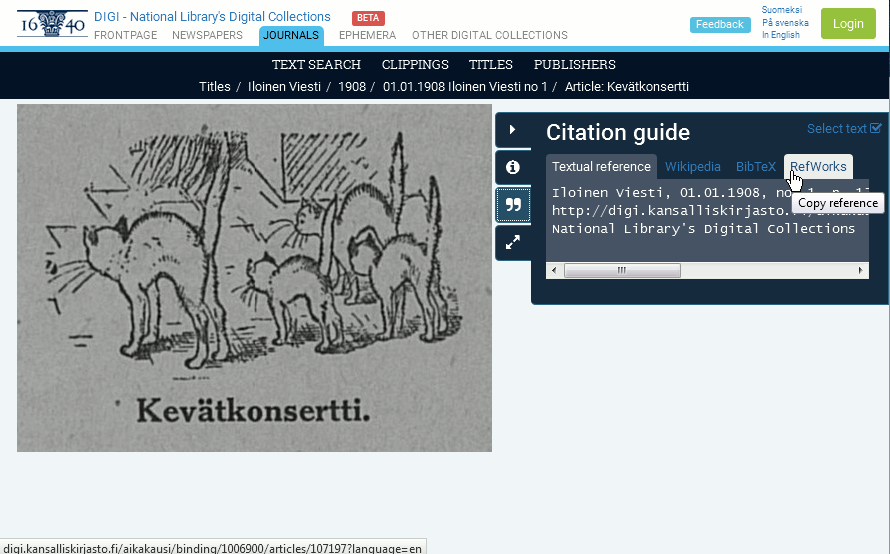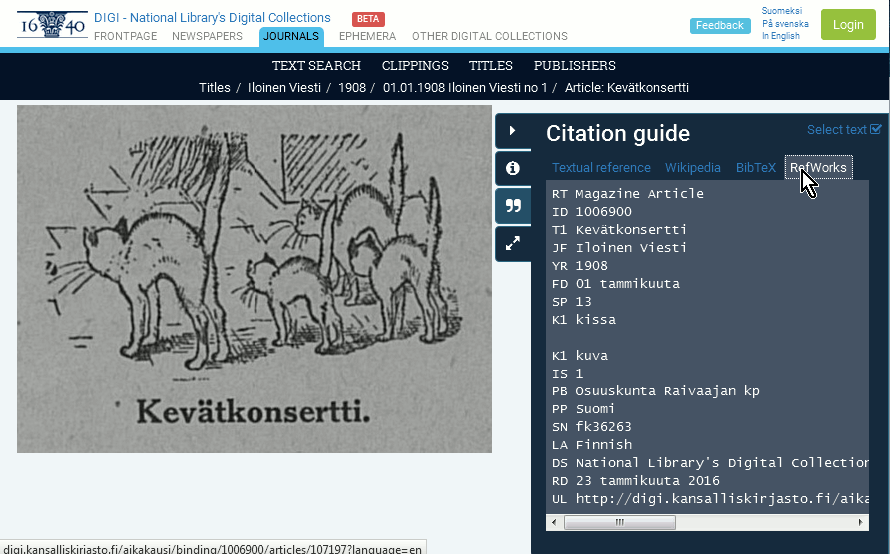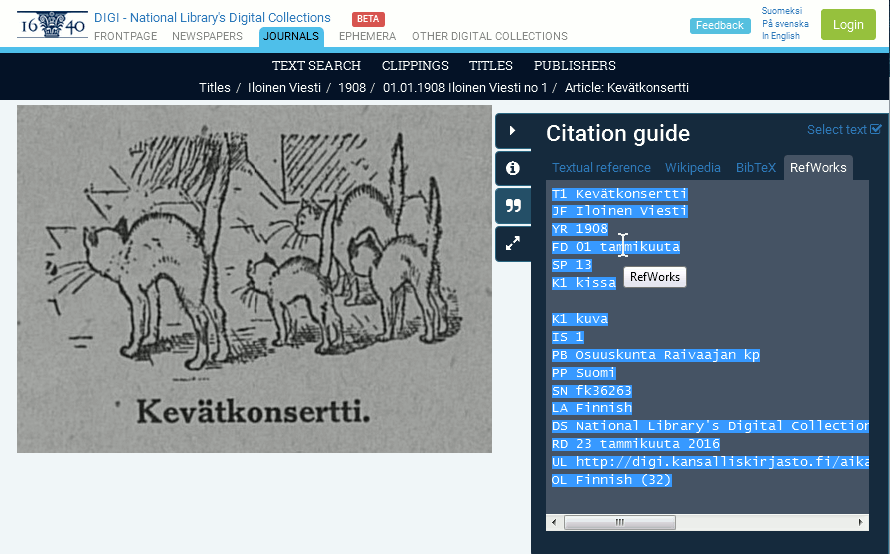
- Then find the ” – quote icon and click that to open reference view
- Then go to RefWorks – tab, and copy the text of the field to your clipboard.
You are done for digi’s side.
Digi.kansalliskirjasto.fi and using references
Then in RefWorks, you can import the copied text to your reference list.
Creating new reference in RefWorks
- Login to RefWorks
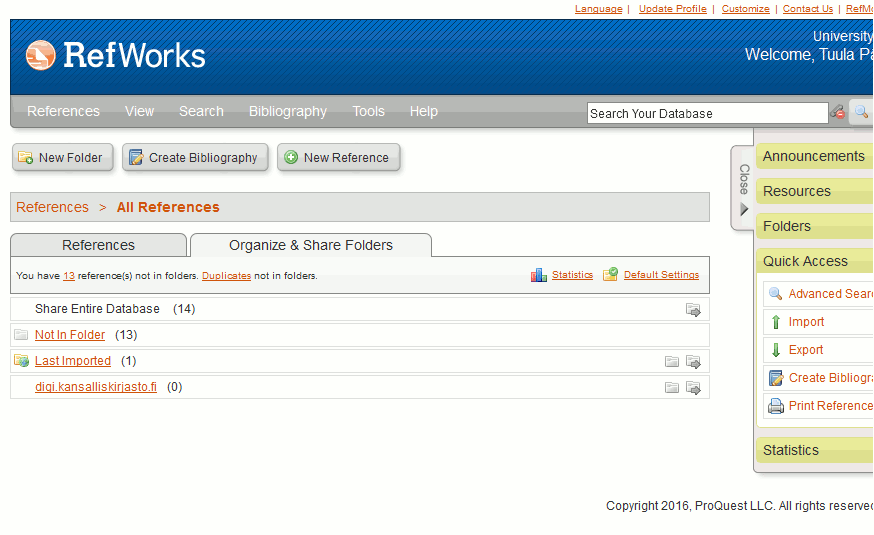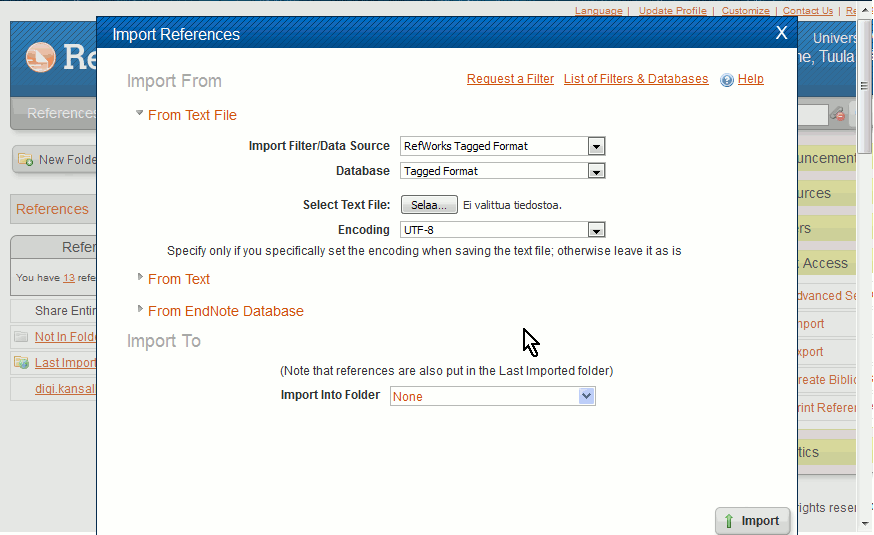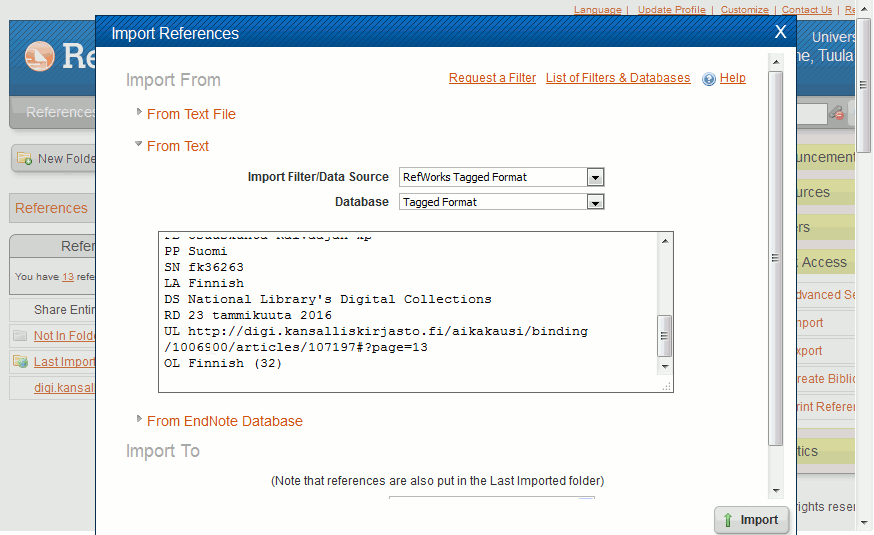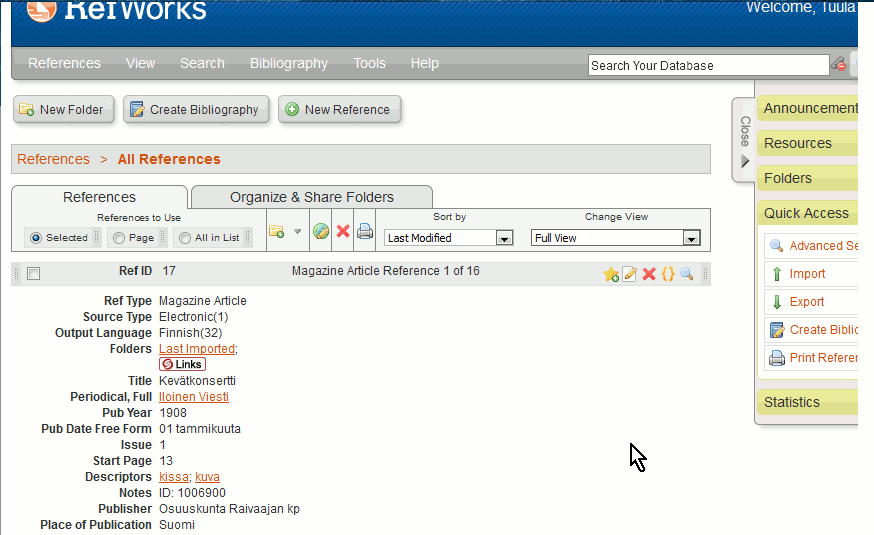
- In RefWorks, click import from the right, and then select ‘From text’ in the given popup
- Paste the citation info from the clipboard to the field and click Import.The new citation is stored and is viewable in your list and you can use it in your articles.
What about BibTex?

BibTex is the another alternative for references, you can the reference via the “- tool and copy entry to your bibliography.