
Tiivistelmä: TensorFlow:lla voi pienten alkusvalmistelujen jälkeen luokitella myös sanoma- ja aikakauslehtien kuvia. Taustaa
Kuvitusten luokittelua – miksi?
Digitalia-projektissa tavoitteena on myös tutkia hiukan kuinka sanoma- ja aikakauslehtien erilaisia osakohteita, kuten kuvituksia voisi käsitellä ja tehdä helpommaksi löytää. Aiemmin digiin on tehty mahdollisuuksia hakea kuvituksia aineistoihin vuoteen 1920 asti, ja viime vuoden lopulla tätä jatkettiin 1929 asti ja osin pidemmällekin. Kuvitusten haku pohjautuu nyt jälkikäsittelyn työhön, joka viedään tietokantaan ja lisätään hakuindeksiin. Nyt suunnitteilla on löytää keinoja kuinka kuvituksia voisi tehdä paremmin löydettäväksi. Yksi tapa tähän on takastella itse kuva-aluetta tarkemmin ja selvittää kuvan sisältöä, esimerkiksi mikä olisi kuvan pääsisältö. Tätä varten nyt kuva-alueita on poimittu erilleen, jotta olisi mahdollista tehdä kokeiluja kuvien luokittelussa. Ongelma on osittain eri kuin modernien kuvien tai vaikka valokuvien luokittelussa, koska sanomalehti- tai aikakauslehtiaineisto tuo uutta pohdittavaa esimerkiksi kuvan koon, mahdollisen käytettävän kuvan puskurin tai harmaasävytaustan takia. Alun perin pohdimme, että olisi hyvä jos kuvassa olisi pieni ylimääräinen puskuri, joka antaisi hiukan kontekstia kuvaan, mutta näytti, että jotkin palvelut, jotka tekisivät kuvien luokittelua puskuri voi hämätä esimerkiksi aiheuttamalla kaikkiin kuviin aina avainsanan ‘paperi’ tai ‘teksti’.
TensorFlow
Kuvitusten käsittelyyn yksi mahdollinen koneoppimisratkaisu on Googlen kehittämä TensorFlow-alusta, jota päätimme kokeilla sanomalehtiaineistojen kanssa. Loimme opetusaineiston joistakin tyypillisimmistä kuviluokista, joita sanomalehdistä löytyy kuten ihmiset, rakennukset, kulkuvälineet, ja poimimme jokaiseen luokkaan siihen sopivia sanomalehtikuvia eri lehdistä.
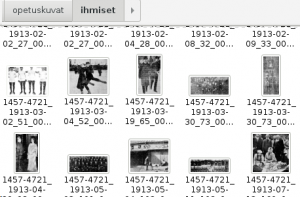
Tensorflow analysoi kuvat omalla ohjelmallaan, joka luo sille kyvykkyyden tunnistaa kuvia joita sille on kerrottu:
python retrain.py --bottleneck_dir=./retrain/bottlenecks \
-model_dir=./retrain --output_graph=retrained_graph.pb \
--output_labels=./retrain/reretrain_labels.txt \
--image_dir ./opetuskuvat --how_many_training_steps=500 \
--summaries_dir=tf_files/training_summaries/"${ARCHITECTURE}
Prosessoinnissa menee hetki, mutta lopputuloksena syntyy tekstitiedosto opetetuista luokista ja ‘verkko’ opetetun aineiston piirteistä. Tensorboard-työkalun avulla voi myös monitoroida kuinka hyvin opetusaineisto voi olettaa toimivan.
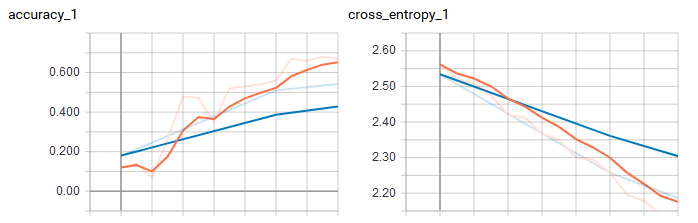
Tämän jälkeen voikin jo kokeilla kuinka TensorFlow luokittelusta selviää kohdeaineiston kanssa. Kohdeaineisto valittiin toisesta lehdestä kuin itse opetusaineisto, jotta näkee hiukan mallin yleispätevyyttä.
python classify_image2.py --model= > luokitusdemo.log &
Saat yhden version ym. skriptistä TensorFlown tutoriaaleista . Oma versiomme tekee hiukan nimeämismuutoksa ja siirtää kuvan halutun luokan mukaiseen alikansioon, josta on helpompi tarkistaa onko luokittelu osunut oikeaan. 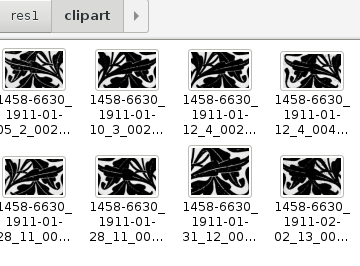 Opetuskuvien määrän, laadun ja kohdeaineistosta riippuu kuinka hyvin luokittelu onnistuu. Selkeät opetuskuvat, jossa kohde löytyisi eri näkökulmista voi olla yksi tapa jolla lopputuloksesta tulee paras mahdollinen. Kannattaa ehkä ajatella että koneoppiminen on hiukan kuin likinäköinen ihminen – suuret selkeät linjat erottuvat parhaiten, mutta tarkemmat yksityiskohdat vaativat hieman siristelyä – useampia opetuskierroksia tai lisää opetusdataa.
Opetuskuvien määrän, laadun ja kohdeaineistosta riippuu kuinka hyvin luokittelu onnistuu. Selkeät opetuskuvat, jossa kohde löytyisi eri näkökulmista voi olla yksi tapa jolla lopputuloksesta tulee paras mahdollinen. Kannattaa ehkä ajatella että koneoppiminen on hiukan kuin likinäköinen ihminen – suuret selkeät linjat erottuvat parhaiten, mutta tarkemmat yksityiskohdat vaativat hieman siristelyä – useampia opetuskierroksia tai lisää opetusdataa.
Muistathan rekisteröityä DHN18-konferenssiin konferenssin kotisivulla ja jos esimerkiksi tällainen ylläoleva kokeilu kiinnostaa, niin ilmoittaudu tiistain 6.3. Miniature histories -työpajaan, jossa lehtiaineistoja pohdimme. Kiinnostavaa olisi tietää mitkä kuvitusten pääluokat olisi kiinnostavia? Mistä löytyisi hyvää opetusaineistoa jotta voisimme sanoma- ja aikakauslehtien kuvitusten hakuun tehdä uusia mahdollisuuksia? Soveltuisivatko sanomalehtien kuvat joihinkin tutkimuskäyttöihin? Löydät TensorFlow:n perusasetukseen, joka oman esimerkkimme taustalla myös toimii ohjeita sekä Linuxille että Windowsille, jota voit kokeilla jo etukäteen.



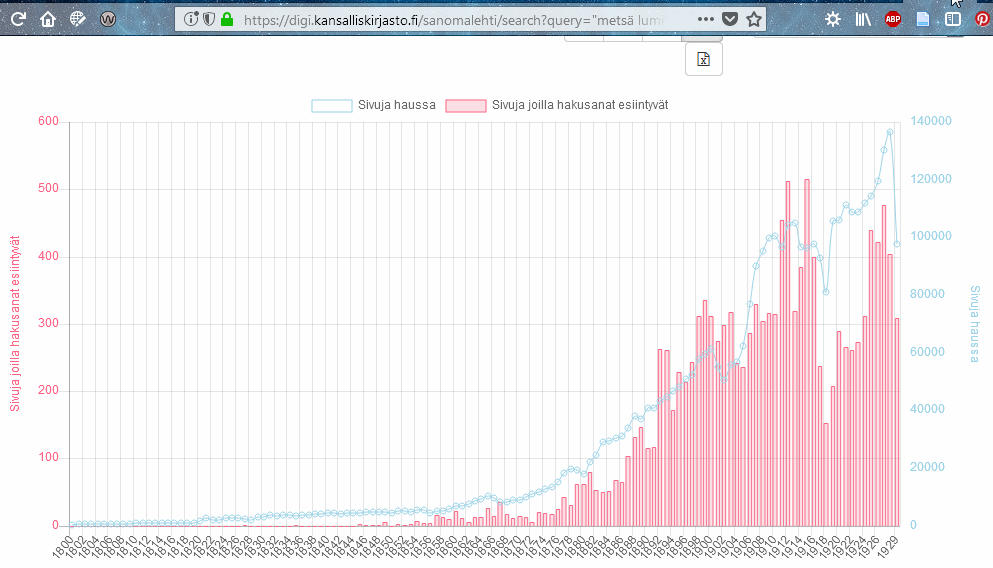

 Pick date and newspaper if want to target that specific one. Free text search and all of its options are useful if you have specific search idea, but want to see across newspapers (or journals) what is found from it.
Pick date and newspaper if want to target that specific one. Free text search and all of its options are useful if you have specific search idea, but want to see across newspapers (or journals) what is found from it.