Viimeisimmät muutokset käytössä olevaan malliin
- Vaihtoehtoisen smolttien lähtemistodennäköisyyden luonnetta kuvaavan Beta-jakaumamallin lisääminen
- Mallitekniset muutokset pyydystettävyyden laskemisessa
Käytössä oleva mallimme perustuu pääpiirteittäin edelleen alkuperäiseen rakenteeseen ja eri malliversioiden yhdistämiseen BMA:ta hyödyntäen. Seuraavassa esitellään mallin eri osat ja tehdyt muutokset (kiitos Leolle selkeistä kommenteista BUGS-skriptissä!).
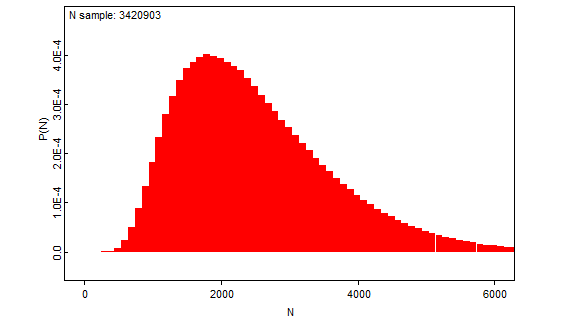
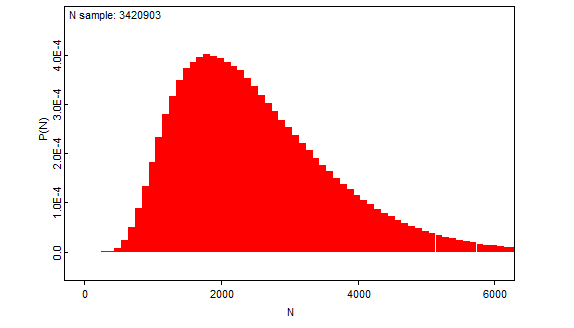
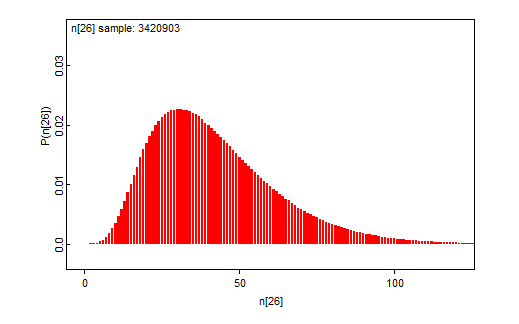
Vuosittainen kokonaisvaellusmäärä
Muuttavien smolttien kokonaismäärän (N) odotusarvon priorina käytössä on edelleen kolmen asiantuntijaarvion keskiarvo (2600), jonka on odotettu tulevan ainoastaan positiivisia arvoja tuottavasta katkaistusta, kokonaisluvuiksi pyöristetystä normaalijakaumasta.
N<-round(cN)
cN~dnorm(2600, prec_N)I(1,)
prec_N<-pow(sd_N, -2)
sd_N<-2000
Kokonaisvaellusmäärän priorin määrittelemiseksi voisi myös asiantuntijaarvioiden sijaan tai lisäksi hyödyntää tietoa edellisvuosina jokeen nousseiden meritaimenten määristä, joko laskemalla nousukkaiden smolttituotantopotentiaali mortaliteettitekijät huomioiden, tai takautuvasti merikuolleisuuden kautta arvioiden aikaisempien vuosien mereen päätyneiden smolttien määriä.
Lähtemistodennäköisyys
Muuttointensiteetin tai päivittäisen lähtemistodennäköisyyden (p) kuvaamiseksi on tähän mennessä käytetty kolmea eri todennäköisyysjakaumaa; tasajakauma, normaali ja log-normaali. Vaihtoehtoisia malleja on ajettu erikseen rinnakkain ja myöhemmin yhdistettynä mallikeskiarvoistamista (BMA) käyttäen. Nykyisessä mallissa näiden kolmen jakauman lisäksi neljäntenä vaihtoehtona on käytetty beta-jakaumaa. Beta-jakauma (Beta distribution – Wikipedia) on intervallille [0,1] määritelty, melko mukautuva todennäköisyysjakauma, jonka muodon määrittää tiheysfunktion alfa ja beta parametrit. Beta-jakauma sopii usein osuuksien sattumanvaraisen käytöksen mallintamiseen.
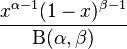
Mallissa on tarkastelujakson jokaisen päivän (1,2,3,…60) huomioivan silmukan (“for-loop”) sisällä määritelty lähtemistodennäköisyys neljällä vaihtoehtoista muodolla( p[i,1], p[i,2], p[i,3] ja p[i,4]). Eri p-funktioiden indeksöinti (1–4 hakasulkeiden sisällä) tulee mallissa myöhemmin käyttöön, kun vaihtoehtoiset, ainoastaan muuttointensiteetin muodon määrittelyssä toisistaan eroavat neljä osamallia sisällytetään päämalliin. Kaikissa muissa p:n funktioissa, paitsi tasajakauma-muodossa, on käytetty yhteistä odotusarvon parametriä (myy_p), joka on määritelty skriptin lopussa yhdessä eri funktioden hajontaparametrien kanssa.
for(i in 1:60) {
# p tasajakaumalla
p[i,1]<-1/60
# p normaalijakaumalla
pl[i] <- exp(- pow((i-myy_p)/sd_p,2)*0.5)
p[i,2] <- pl[i] / sum(pl[1:60])
# p log-normaalijakaumalla
pn[i] <- (1/i)*exp(- pow(log(i)-location, 2) / scale)
p[i,3] <- pn[i] / sum(pn[1:60])
# p beta-jakaumalla
pbi[i]<-pow(i/60,myy_p*b_eta/60)*pow(1-i/60,(1-myy_p/60)*b_eta)
Koska yllä olevasta beta-jakauman funktiosta puuttuu normalisointivakio B (beta-funktio) nimittäjästä, varmistetaan että beta summautuu yhteen yli päivien, näin:
p[i,4]<-pbi[i]/sum(pbi[])
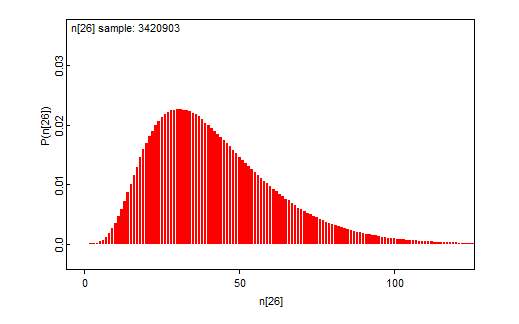
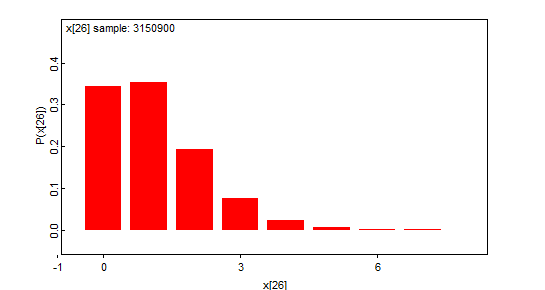
Lähtevien smolttien määrät
Seuraavaksi mallissa määritellään lähtevien smolttien päivittäiset (i) määrät (n) kokonaismäärästä (N) binomijakaumalla eri lähtemistodennäköisuusmalleille 1,2,3,4, ja varmistetaan, ettei päivittäiset lukumäärät ole nolla, koska se aiheuttaisi ongelmia kokonaispyydystettävyyn määrittelyssä käytettävässä binomijakaumassa.
n2[i]~dbin(p[i,model],N)
n[i]<-n2[i]+1
}
Saalis ja pyydystettävyys
Dataa on tähän mennessä kerätty kahdella eri pyyntivälineellä (smolttiruuvi ja rysä), ja niiden vaikutukset on huomioitu mallissa jo aikaisemmin. Ruuvi on ollut käytössä koko tarkasteluajan tähän asti kun taas rysä otettiin käyttöön vasta myöhemmin, jonka jälkeen se otettiin pois mutta on nyt taas pyynnissä. Periaate kahden eri välineen kokonaispyyntihehon laskemisessa on edelleen sama kuin aiemmin:
P(kala jää ruuviin TAI rysään) = P(kala jää rysään) + P(kala jää ruuviin) – P(kala jää ruuviin JA rysään)
Muutokset päivittäisen kokonaissaaliin ja pyydystettävyyden arvionnissa ovat malliteknisiä, tehden koodista elegantimman ja mallista mahdollisimman kevyen. Uuden rakenteen myötä myös datan taulukkomuoto on muuttunut, sisältäen seuraavat sarakkeet: ScrewX[] (ruuvin saalis), FykeX[] (rysän saalis), tagged[] (merkityt kalat), Screw_op[] (ruuvin käyttöstatus), Fyke_op[] (rysän käyttöstatus), ScrewR[] (ruuvin takaisinpyyntisaalis), FykeR[] (rysän takaisinpyyntisaalis) ja TotalX[] (kokonaissaalis). Mallissa on tarkasteluajan jokaisen tähänastisen ja seuraavan päivän (1,2,3,…days+1) huomioivan silmukan sisällä määritelty päivittäinen kokonaissaalis (TotalX[d]), päivittyvä kokonaispyyntiteho (Total_q[d]), ruuvin päivittäinen saalis (ScrewX[d]), ruuvin päivittyvä pyyntiteho (Screw_q[d]) ja rysän päivittyvä pyyntiteho (Fyke_q[d]) seuravanlaisesti:
for(d in 1:days+1) {
# Kaikkien havaittujen smolttien yhteenlaskettu määrä päivänä d noudattaa binomijakaumaa parametreilla kokonaispyydystettävyys (Total_q[d]), päivittäiset muuttavat smoltit (n[d])
TotalX[d]~dbin(Total_q[d],n[d])
Total_q[d]<-Screw_q[d]+Fyke_q[d]-Screw_q[d]*Fyke_q[d]
# Ruuvin havainnot noudattavat poisson -jakaumaa parametrilla odotusarvoiset lähtevät smoltit (binomijakaumalla tulee ongelmia, sillä päivittäiset lähtevät määrät saattavat saada arvoja nolla)
ScrewX[d]~dpois(screw_muX[d])
# Odotusarvoiset lähtevät smoltit päivänä d (screw_muX[d]) määrittyvät ruuvin suhteellisella teholla (Screwprop[d])*kuinka moni jää kaiken kaikkiaan kiinni (TotalX[d])
screw_muX[d] <- Screwprop[d]*TotalX[d]
#Ruuvin suhteellinen teho on ruuvin teho jaettuna kokonaisteholla (ruuvi JA rysä)
Screwprop[d]<-Screw_q[d]/Total_q[d]
# Ruuvin suhteellista tehoa päivitetään vain kun ruuvin on käytössä (indikaattorifunktio screw_op saa arvoja 0, kun ei käytössä, arvoja 1 kun käytössä)
Screw_q[d]<-q_S*Screw_op[d]
# Rysän pyydystettävyys päivittyy samalla indikaattorifunktion logiikalla
Fyke_q[d]<-q_F*Fyke_op[d]
# Priori määrälle merkittyjä kaloja (tämä on joku tekninen eli laskennallinen yksityiskohta)
tagged[d]~dbin(1,1000)
}
Seuravaksi mallissa määritellään, kuinka pyydystettävyys päivittyy uudelleenpyydettyjen havainnoilla. Päivät (d) kulkevat toisesta päivästä, koska vasta siitä lähtien on mahdollista pyydystää päivänä 1 merkitty kala.
for(d in 2:days+1) {
# Rysän uudelleenpyytämien kalojen havaintojakauma noudattaa binomijakaumaa parametreilla rysän pyyntiteho(Fyke_q[d]) , edellisenä päivänä merkityt kalat (tagged[d-1])
FykeR[d]~dbin(Fyke_q[d],tagged[d-1])
# Ruuviin voi periaatteessa jäädä kaikki ne kalat, jotka on edellisenä päivänä merkitty, mutta jotka eivät jääneet ruuviin
Screw_nR[d]<-tagged[d-1]-FykeR[d]
# Ruuvin pyydystettävyyden havaintojakauma noudattaa binomijakaumaa parametreilla ruuvin pyydystettävyys (Screw_q[d]), ja edellisessa kaavassa määritellyt mahdolliset määrät (Screw_nR[d])
ScrewR[d]~dbin(Screw_q[d],Screw_nR[d])
}
Rysän pyydystettävyyden prioria (q_F) muutettiin säilyttäen pseudohavaintojen suhteet. Arvoilla 1 ja 4 voidaan tehdä prioriarvio epävarmemmaksi siksi, ettei mandariinikoetta ole toistettu rysälle. Samat suhteet mallintavat kuitenkin ennakkokäsitystä, jonka mukaan rysä ja ruuvi pyydystävät yhtä hyvin. Tämän oletuksen uskottavuudesta voidaan kuitenkin olla eri mieltä, vaikka pyydysten ominaisuuksien eroja ei tiedetäkään, koska rysä pyydystää eri kohdassa jokea ruuviin verrattuna ja koska on epätodennäköistä että smoltit ovat tasaisesti jakautuneita koko virran leveydeltä jo mandariinikokeen tulostenkin perusteella.
q_F~dbeta(1,4)
q_S~dbeta(2,8)
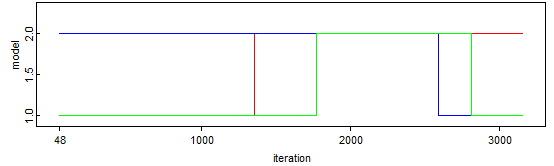
Eri osamallejen sisällyttäminen ja mallikeskiarvoistaminen
Viimeisessä tätä edellisessä versiossa yhdistettiin jo eri lähtemistodennäköisyyksien määrittelemät osamallit yhdeksi malliksi Bayesilaisella mallikeskiarvoistamisella (BMA). Ainoa muutos tämän suhteen tähän malliin, on neljännen mallin, eli lähtemistodennäköisyyden beta-jakaumamallin lisääminen, joka tehtiin seuraavanlaisesti:
# Priori mallin BMA:lle
model~dcat(z[1:4])
# Tässä määritellään prioritodennäköisyys eri mallien totuudelle
z[1]<-1/4 # Tasajakaumamalli
z[2]<-1/4 # Normaalijakaumamalli
z[3]<-1/4 # Log-normaalijakaumamalli
z[4] <-1/4 # Beta-jakaumamalli
# Tästä saadan eri mallien posterioritodennäköisyydet
Z[1]<-equals(model, 1)
Z[2]<-equals(model, 2)
Z[3]<-equals(model, 3)
Z[4] <- equals(model,4)
Lähtemisintensiteettien priorit
myy_p~dnorm(25,tau_myy)I(0.01,)
tau_myy<-pow(7,-2)
sd_p~dnorm(10, tau_sd)I(0.01,)
tau_sd<-pow(5, -2)
scale <- log(1 + pow(sd_p/myy_p,2) )
location <- log(myy_p) -0.5*scale
b_eta~dunif(5,100)
}
Data
list(days=33)
ScrewX[] FykeX[] tagged[] Screw_op[] Fyke_op[] ScrewR[] FykeR[] TotalX[]
0 0 0 1 0 0 0 0
0 0 0 1 0 0 0 0
0 0 0 1 0 0 0 0
1 0 0 1 0 0 0 1
2 0 3 1 0 0 0 2
2 0 2 1 0 0 0 2
0 0 0 1 0 0 0 0
0 0 0 1 0 0 0 0
0 0 0 1 0 0 0 0
1 0 0 1 0 0 0 1
1 0 0 1 0 0 0 1
1 0 3 1 0 0 0 1
0 0 0 1 0 0 0 0
2 0 2 1 0 0 0 2
1 0 1 1 0 0 0 1
0 1 1 1 1 0 0 1
0 1 0 1 1 0 0 1
0 1 0 1 1 0 0 1
1 1 3 1 1 0 0 2
3 2 5 1 1 0 0 5
6 2 8 1 1 0 0 8
4 0 4 1 0 0 0 4
2 0 2 1 0 0 0 2
2 0 2 1 0 0 0 2
1 0 1 1 0 0 0 1
3 0 3 1 0 0 0 3
2 0 2 1 0 0 0 2
1 0 2 1 0 1 0 1
3 0 3 1 0 0 0 3
1 0 1 1 0 0 0 1
1 0 1 1 0 0 0 1
1 0 1 1 0 0 0 1
2 0 2 1 0 0 0 2
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
NA NA NA 1 1 NA NA NA
END
#BUGS:iin ladattavat eri mallien alkuarvot, hyvä käyttää eri alkuarvoja
list(model=1)
list(model=2)
list(model=3)
list(model=4)
Huomioita lopuksi
Vaikka mallin aktiivinen kehittäminen jäänee lähiaikoina hieman vähäisemmäksi, voisi tulevaisuudessa edelleen yrittää sisällyttää tietoa ympäristömuuttujista (lämpötila, vedenkorkeus, ym) ja niiden vaikutuksista, sekä vaellusmatkan pituudesta ja eri smolttituotantoalueiden (koskien) kapasiteetistä ja sijoittumisesta. Lähiaikoina jatkamme mallin sisällyttämisellä päätösanalyysiin, joka koskee kysymystä Vanhankaupunginkosken padon mahdollista purkamista.