
Historioitsija, tietokirjailija ja ”kirjoittelija” Aleksi Peura aloitti joulukuussa 2021 tietoasiantuntijana Helsingin yliopiston kirjastossa. Uudessa tehtävässään hän auttaa tutkijoita erityisesti tutkimusdatanhallintaan liittyvissä kysymyksissä. Tässä kirjoituksessa Peura kuvaa omia lähtökohtiaan ja humanistitutkijan suhdetta dataan, edeten yhä syvemmälle datanhallinnan maailmaan. Kirjoitus on avaus kuukausittaiselle juttusarjalle, jossa Peura käsittelee datanhallinnan teemoja ”omasta, nyrjähtäneestä humanistin näkökulmastaan”.
Teksti: Aleksi Peura

Kuulemani mukaan olen milleniaali-ikävuosiani vanhanaikaisempi: pidän analogisista medioista, pyrin pitämään kädenmitanetäisyyden uuteen teknologiaan ja toisinaan vaivun nostalgisoinnin valtaan, huokaillen menetettyjen aikojen ja maailmojen perään. Historia-alan koulutukseni on valmistanut minut prosessoimaan suuria linjoja omatoimisesti, tarttumaan ennemmin vuosisadan tai pari vanhaan kirjaan kuin .xml-formaattiin. Toisinaan, oikein huonolle päälle sattuessani, saatan julistautua luddiitiksi ja mutista naavapartaani, kuinka digitalisaation tai jonkin muun nykyajan supertrendin myötä koko yhteiskunta menee rappiolle, taas kerran.
Silti, en vierasta teknologiaa, vaikka olenkin lähtökohtaisesti varautunut sen äärellä. Kuten epäilemättä moni milleniaali, olen räpellellyt tietokoneiden kanssa koko pienen (?) ikäni: monet hienoimmista lapsuusmuistoistani kytkeytyvät tiiviisti tietokoneeseen tai johonkin muuhun (silloin) uuteen teknologiaan. Kuinka säästin kahden markan viikkorahojani vuosia voidakseni ostaa itselleni ensimmäisen Playstationin. Kuinka kuuntelin alle kahdenkymmenen .mp3-kappaleen biisilistaa edestakaisin pelatessani monituntisia Civilization III -sessioita. Kuinka nikkaroin omia – enemmän kuin vähän alkeellisia ja tragikoomisia – biisejäni muinaisella Guitar Pro 5 -ohjelmistolla. Kuinka lukioikänä suuri siivu vapaa-ajasta kului mesessä jauhaen sitä ihteään.
Ehkä tästä dualismistani johtuen olen päätynyt ja hakeutunut uuteen työtehtävääni, mene ja tiedä. Olen siis aloittanut joulukuussa 2021 tietoasiantuntijana Helsingin yliopiston kirjastossa, mutta työtehtäviini ei kuulu niinkään kirjojen hyllyttäminen, vaan tutkijoiden avustaminen tutkimusdatanhallintaan liittyvissä kysymyksissä. Käytännössä kirjoitan sähköposteja, etsin vastauksia, otan haltuun entuudestaan vain summittaisesti tuttua aihepiiriä ja yritän ymmärtää niitä moninaisia tarpeita, joita tutkijoilla on tai voi olla datanhallintaan tai datanhallintasuunnitelmiin liittyen. Mitä tämä kaikki oikeastaan tarkoittaa, sitten?
Aleksi Peura
|
Humanisti ja data
Tehtävänkuvani ytimessä on data, tuo nelikirjaiminen humanistin kauhistus, joka ei aiheeseen paneutumattomalle tunnu tarkoittavan mitään, mutta joka silti ponnahtelee esiin vähän siellä-sun-täällä: on mörököllimäistä big dataa, on hienolta kuulostavaa mutta vierasta metadataa ja on ihan vain dataa itseään, ykkösiä ja nollia jossakin tietokoneen syövereissä. Työtäni ei kuitenkaan ole ymmärtää kaikkea dataa itsessään (pystyyköhän moiseen kukaan?), vaan yritän ymmärtää erilaisia keinoja käsitellä ja hallinnoida dataa sekä ongelmia, joita näihin liittyen saattaa ilmestyä. No, mitä tämä nyt sitten taas tarkoittaa?
Mietitään, että olen hypännyt keski-iän yli suoraan eläkkeelle ja hurahtanut tekemään sukututkimusta. Menen arkistoon lukemaan kirkonkirjoja, joista etsin sukulaisiani. Löydettyäni sukulaisiani kirkonkirjoista, kirjoitan heidän nimensä ylös muistikirjaani piirtämäni sukupuun jatkoksi. Tässä esimerkissä tutkimukseni (raaka)dataa ovat kirkonkirjat: ne itsessään eivät ole mitään muuta kuin pelkkiä epäselvällä käsialalla kirjoitettuja nimiä, päivämääriä ja vuosilukuja. Näitä nimiä ja ajankohtia lukemalla ja sukulaisiani etsiessäni prosessoin dataani: prosessointini lopputuloksena on uutta dataa, vähemmän raakaa sellaista, eli muistiinpanoni.
Data on siis tietoa, muovailuvahaa joka itsessään ei esitä tai ole mitään muuta kuin (sitä) itseään. Vain muotoilu (eli tutkimusprosessi) tekee tuosta datavahasta merkityksellistä. Onkin tyystin toinen asia, miten tuo muotoilu tarkalleen tapahtuu – sen puolen jätän suosiolla tutkijoille, metodeja hallitseville erityisasiantuntijoille.
Kohti datan hallintaa – tiedostomuodot
Kuvailemani esimerkki sukututkijasta on historioitsijalle tyypillinen: kaikki on oletusarvoisesti analogista, muistiinpanotkin tehdään käsin, ja suuria kokonaisuuksia hahmotetaan omatoimisesti, siellä omien aivojen sopukoissa. Silti, tutkimusprosessin näkökulmasta data on dataa, vaikka se ei olisikaan tietokoneen syövereissä. Pohjimmiltaan kirkonkirjat ovat samanlaisia kuin kyselytutkimuksella kerätyt vastauslomakkeet tai lääketieteellisen tutkimuksen geenisekvenssit, mitä nyt vain merkittävästi vanhanaikaisempia. Kaikki nämä – ja monet muut mahdolliset datatyypit – ajavat saman asian tutkimusprosessissa: ne ovat sitä muovailuvahaa, jolla omat tutkimuslinnoitukset (tai ainakin muodottomat möykyt, koska ei muovailuvahasta juuri muuta saanut tehtyä, eihän?) nikkaroidaan kasaan.
Tutkimusdataan liittyy kuitenkin monia kysymyksiä, joihin voi vastata yleisellä tasolla, mutta jos oikein hyödyllisiä ollaan, turvaudutaan fraasiin ”no se on kovin tapauskohtaista”. Esimerkiksi niinkin yksinkertainen asia kuin tiedostomuoto on ”kovin tapauskohtaista”, ainakin toisinaan. Palataan sukututkimusesimerkkiini, mutta sillä erolla, että olen tällä kertaa tehnyt muistiinpanoni analogisen kynä-ja-paperi-menetelmän sijaan tietokoneella – mutta kuinka, tarkalleen? Olenko tallentanut ne taulukko-ohjelmaan – jos kyllä, mitä tiedostomuotoa olen käyttänyt ja olisiko jokin toinen parempi? Hamletkin sitä aikanaan pohti: Ollakko .csv vaiko ei, siinäpä vasta kysymys. Ehkäpä ne ovat tekstinkäsittelyohjelmassa – jos näin, mihin muotoon olen tiedoston tai tiedostot tallentanut ja pitäisikö kuitenkin käyttää taulukko-ohjelmaa? Kaikissa tiedostomuodoissa on puolensa, puolesta ja vastaan tietenkin, eikä minkään valitseminen toisen sijasta ole väistämättä sen oikeampi valinta kuin jokin toinen: valinta on tehtävä tarpeiden, käyttötarkoitusten ja hyödyllisyyksien perusteella ”kovin tapauskohtaisesti”.
Syvemmälle datanhallintaan – sensitiivinen data
Tiedostomuotorumba on vielä sieltä helpoimmasta päästä, koska kaikki tietänevät kuitenkin suunnilleen Excelin ja Wordin periaatteellisen eron, vaikka .csv, .xls, .odt ja .doc eroineen eivät välttämättä olisikaan yhtä tuttuja. Entäs kun aletaan puhua erilaisista tallennuspalveluista, joissa tuota dataa säilytetään tutkimuksen aikana: kuinka moni tuntee ePoutan, OneDrvien, Umpion ja Z-aseman erot edes samalla summittaisella asteella kuin Excelin ja Wordin tai näiden tiedostomuotojen erot?
Mitä väliä mihin sen datan tallentaa, eikö niin? Dataahan tietokoneet ja internet ovat täynnä – mitä väliä näillä sukututkimukseni muistiinpanoilla ja haastatteluilla? Paljonkin: jos datasta on mahdollista tunnistaa elossa olevia ihmisiä, tuo data sisältää henkilötietoja ja tällöin datan tulee olla riittävän vahvasti suojattua, sen käyttö tarkasti sovittua ja se pitäisi vielä jossain vaiheessa anonymisoidakin. Kaikki datan suojaamiseen ja anonymisoimiseen liittyvä on sitä tärkeämpää mitä korkeariskisempää aineisto on: esimerkiksi henkilötunnus on vahva, suora tunniste ja vielä melkoisen korkeariskinen sellainen, koska jos se päätyy vääriin käsiin, henkilölle syntyy siitä paljon vahinkoa. Samanlaisia korkeariskisiä eli sensitiivisiä aineistoja ovat esimerkiksi geneettiset tiedot, uskonnolliset ja poliittiset näkemykset sekä etninen tausta. Kaikki tällainen aineisto on suojattava erittäin huolellisesti, mikä tarkoittaa aineiston tallentamista erittäin turvalliseen paikkaan, ja aiemmin mainitsemastani neljästä palvelusta – ePouta, OneDrive, Umpio ja Z-asema – vain kaksi soveltuu korkeariskiselle sensitiiviselle datalle… ja niistä vain toinen tarjoaa varmuuskopiointia ja versiokontrollia, mutta on samalla maksullinen palvelu ja kaikki tämä on tärkeää ”kovin tapauskohtaisesti”.
Kaikki datan suojaamiseen ja anonymisoimiseen liittyvä on sitä tärkeämpää mitä korkeariskisempää aineisto on.
Käytännössä kaikessa ihmistieteiden alalla tehtävässä tutkimuksessa käsitellään dataa, josta on mahdollista tunnistaa ihmisiä, koska tunnistaminen voi tapahtua myös kollaasimaisesti eli epäsuorasti. Jos henkilö kertoo yhdessä kohdassa asuvansa alle kymmenentuhannen asukkaan Perähikiän kunnassa, toisaalla olevansa lapseton 39-vuotias nainen ja kolmannessa kohdassa harrastavansa beaglekoirien kasvatusta, shakkinyrkkeilyä ja kuviokelluntaa, nämä kaikki asiat eivät voi kuvata kovin montaa ihmistä, vaikka yksittäin katsottuna mikään tiedoista ei ole luonteeltaan sensitiivinen. Kollaasimaisesti tarkasteltuna käsillä kuitenkin on henkilötietoja, koska oikea, elossa oleva ihminen on tunnistettavissa. Jos ja kun tutkimusdataa sitten anonymisoidaan, sitä ei voi tehdä pelkästään korvaamalla nimi toisella (tätä kutsutaan pseudonymisoinniksi eikä se riitä kuin väliaikaiseksi ratkaisuksi) ja poistamalla syntymäaikoja, henkilötunnuksia tai muita vahvoja suoria tunnisteita, vaan kaikki on arvioitava kokonaisuuden kannalta ja ”kovin tapauskohtaisesti”.
Vielä syvemmälle: dataan liittyvät oikeudet
Vielä yksi esimerkki: tutkimuskohteiden oikeudet. Kuten kaikki internettiä viime vuosina pläränneet (eli about kaikki) tietävätkin, GDPR (General Data Protection Regulation, EU:n yleinen tietosuoja-asetus) vaatii klikkaamaan boksia ”hyväksy kaikki evästeet” tai klikkaamaan useammin päästäkseen klikkaamaan ”salli vain välttämättömät evästeet”. Todellisuudessa GDPR on paljon muutakin kuin pakollinen pop-up-ikkuna: sen tehtävänä on antaa oikeus ja valta itseä koskevasta datasta henkilölle itselleen. Periaatteessa – ja käytännössäkin, ilmeisesti – voit klikkailla about parituhatta kertaa (en ole tsekannut, mutta helpoksi tällaisia juttuja ei koskaan tehdä) päästäksesi vapaavalintaisen sosiaalisen median palvelun lomakkeelle tai alasivulle, josta voit vaatia kaikkea itseäsi koskevaa tietoa nähtäväksesi – ja tuon palvelun pitää antaa sinulle tuo data nähtäväksi. Sama pätee myös tutkimuskohteita: jos tutkimuksessa on vaikkapa haastateltu 39-vuotiasta perähikiäläistä naista, tutkijan on informoitava selkeästi, yksiselitteisesti ja yleisymmärrettävästi (eli ilman tutkimusalan omaa jargonia) häntä kerättävästä datasta, sen käyttämisestä ja säilyttämisestä. Tämän naisen tulee antaa eettinen tai juridinen oikeus tutkijalle käyttää kerättyä dataa ilmoitetulla tavalla, ja juridisen oikeuden hän voi vetää myös pois ja vaatia (tutkimusdatassa) unohdetuksi tulemista. Naisella on siis oikeus häntä koskevaan dataan.
Vastaavasti myös tutkimuslaitoksilla tai -rahoittajilla voi olla oikeus kerättyyn tutkimusdataan kokonaisuudessaan. Jos, esimerkiksi, oman tutkimusyksikön tai yliopiston ulkopuolisia henkilöitä tai tahoja otetaan mukaan tutkimukseen, pitäisi käsillä olla tarkkaan harkittuja ja huolellisesti muotoiltuja (sekä mielellään juristeilla luetettuja) datanhallintasopimuksia, jotka pitäisi sitten vielä tietenkin allekirjoittaa. Samoin pitäisi miettiä etukäteen, mm. että kuka on datanhallitsija, kuka on vastuussa tietovuodon tapauksessa ja kuka omaa oikeudet kerättyyn dataan. Kaikki tämä on, jälleen, ”kovin tapauskohtaista”.
Ja näitä ”kovin tapauskohtaisia” juttujahan sitten riittää. Ja kaikista näistä tulisi omassa työssäni tietää jotain, mielellään paljon. Ja tietenkin kaikilta tieteenaloilta. Ja kaikkien palveluiden erikoisuuksista. Ja tutkimusetiikasta – tutkimusjuridiikkaa tietenkään unohtamatta.
Kaikkea muuta kuin byrokrattisia turhakkeita
Kuinka me datatiimiläiset sitten pystymme sanomaan mikä kaikki ”kovin tapauskohtaisista” tiedoista on kenellekin tärkeää? Telepatiaa tarvitaan onneksi vain harvoin, sillä jatkuvasti yleistyvä työkalu tutkimusrahoituksen hakemisessa ja saamisessa ovat datanhallintasuunnitelmat (DMP, data management plan), jotka ovat kaikkien tutkijoiden ehdottomia suosikkijuttuja eikä kukaan pidä niitä pisaraakaan byrokraattisina turhakkeina. Olen toki sarkastinen (konsensus tutkijoiden keskuudessa tuntuu olevan, että DMP:t ovat kafkamaisia painajaisia), vaikka todellisuudessa näinhän ei pitäisi olla: DMP:t ovat tärkeitä ja hyödyllisiä. Niistä on etua tutkijalle, koska ne auttavat suunnittelemaan tutkimuksen aikana syntyviä ongelmia, jotka voivat olla muun muassa:
- datalogistisia (tallennusratkaisut, varmuuskopioinnit…)
- juridisia (tutkimuskohteiden informointi, tutkimusryhmän/-ryhmien väliset sopimukset…)
- eettisiä (datan sensitiivisyys, datan riskisyys…)
- tutkimuksen läpinäkyvyyteen liittyviä (datan tai metadatan avaaminen muille tutkijoille tutkimuksen jälkeen).
Ilman DMP:n tekemistä – ja valitettavan monesti sen tekemisestä huolimatta – tutkijoille tulee tutkimusprosessin aikana ikäviä tutkimusdataan liittyviä yllätyksiä: siis kuka olisi uskonut, että pilvipalvelun käyttäminen voi maksaa monia satoja tai tuhansia euroja joka vuosi! Kenen palkasta tämä höylätään pois?
DMP:t on tarkoitus tehdä tutkijan ja tutkimusryhmän tarpeisiin, kartoittamaan datanhallintaan liittyviä pulmia tai puutteita, mutta valitettavan usein ne tehdään ”koska on pakko” ja niihin kirjoitetaan ”se mitä rahoittajien suunnalla halutaan kuulla”. Tämä on tietenkin täysin väärä asenne: DMP ei ole byrokraattista pakkopullaa, vaan työväline siinä missä tutkimusdata itsekin. DMP:n tehtävänä on taata, että tutkimuksessa tuotettu data on käyttökelpoista tutkimuksen aikana sekä sen jälkeen ja että lukuisat eettis-juridis-tietotekniset ”kovin tapauskohtaiset” ratkaisut on tiedostettu ja mielellään ratkaistu.
DMP ei ole byrokraattista pakkopullaa, vaan työväline siinä missä tutkimusdata itsekin.
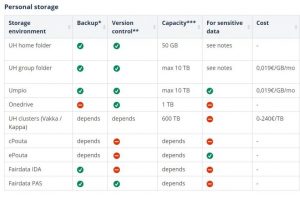
DMP:n kanssa ei tarvitse olla yksin, vaan – kuten olettaa kenties tässä vaiheessa tekstiä saattaa – sitä varten datatiimi on olemassa: me kommentoimme, tarkistamme ja muutoinkin autamme DMP:n kanssa… ja siten myös tutkimusdatanhallinnassa. Valitako Umpio vai SD Connect? Vilkaise tätä taulukkoa, ja jos vastaus ei selkene, laita viestiä meille! Mitä kaikkea se GDPR vaatiikaan? Lukaise lisää täältä ja jos vastaus ei selkene, laita viestiä meille (tai HY:n juristeille)! Jos henk.koht. yhteydenotto kuumottelee, meillä on myös DMP-työpajoja sekä luentomittaisia perehdytyksiä tutkimusdatanhallinnasta eli RDM:stä (research data management), joiden on tarkoitus auttaa alkuun pääsemisessä ja tarjota pohjatietoja.
To be continued…
Tämä teksti on vasta alku, monessakin mielessä. Yksi mielistä on se, että tämä teksti aloittaa täällä Think Open -blogissa uuden juttusarjan, Humanisti datamaailmassa, jonka tiimoilta julkaistaan teksti kerran kuukaudessa. Jokainen teksteistä käsittelee jotakin datanhallinnallista kysymystä omasta, nyrjähtäneestä humanistin näkökulmastani. Pysykää siis linjoilla, samalla bat-kanavalla, samaan bat-aikaan.
Humanisti datamaailmassa -kirjoitussarja: