
”Tutkijan näkökulmasta oman tutkimuksen ja sen datan näkyvyys on ehdottomasti hienoa, mutta saattaa tuntua tutkimusta tehtäessä painajaismaisen turhauttavalta: tässä minulla on tätä dataa, jota käsittelemällä tutkimustulokseni löytyvät, ja haluan vain tehdä tutkimustani – miksi siis käyttäisin aikaani kirjoittamalla auki jokaisen datan perustiedot?” Kirjoitussarjansa kolmannessa osassa Aleksi Peura on datanhallinnan perusasioiden äärellä: miksi metadataan kannattaa suhtautua vakavasti, vaikka se tuntuisi luotaantyöntävältä? Luvassa hillopurkkivertauksia, sivupolkuja ja metadatan kuvailua.
Teksti: Aleksi Peura

Business-maailmassa vuosi 2021 muistettaneen epäilemättä yhtäältä NFT-kaupan läpilyönnistä (NFT:t ovat käytännössä high-tech-versioita kuiteista), toisaalta Facebook-yhtiön nimenvaihdoksesta ja siihen liittyvästä visioinnista. Yhtiö, joka aiemmin tunnettiin sen lippulaivasomealustan nimellä, on nykyään nimeltään Meta. Uuden nimen alla yhtiö on visioinut uutta universumia, metaversumia, jonka täytyy olla todella hieno konsepti, koska kovasta yrittämisestäkään huolimatta en saa siitä muuta tolkkua kuin, että se on teknisesti kompleksisempi versio Second Lifesta. Omaan korvaani koko (Neal Stephensonilta lainattu/omittu/pöllitty) metaversumi-höpinä kuulostaa ylimonimutkaiselta jargonilta, jota ympäriinsä roiskiessa voi yrittää piilottaa sen tosiasian, että puhuu täyttä puuta heinää – toisaalta, olenkin humanisti, en teekkari, siispä mitäpä minä businesspöhinästä tietäisin?
On Facebookin uudelleennimeämisestä ja metaversumi-roiskimisesta mitä mieltä tahansa, sana meta on ilmeisen muodikas ja viimeistään 2021 se nousi ainakin teknologiasta innostuneiden kansalaisten huulille. Elinikäisenä nörttinä meta on tullut minulle tutuksi etenkin pelien kautta: kun puhutaan, että jokin peli saa ”metaleveleitä”, tarkoitetaan, että pelin pelaamisesta tulee peli itsessään. Mietitään vaikkapa kansallisurheiluamme, ristiseiska-korttipeliä: jos peliä pelaa sama porukka toistuvia kertoja, pelaamiselle alkaa syntyä oma lomittaispelinsä. Kuinka joku pihtaa järjenvastaisesti patakolmosta; kuinka pantti kiertää kädestä käteen eikä kukaan suostu laittamaan kortin korttia pöytään, koska silloin joutuisi luopumaan omasta pihtikortista eikä pelikaverin lupaus oman pihtikortin pelaamisesta ole koskaan ollut minkään arvoinen; kuinka kaikki tietävät, että tähänhän se jossakin vaiheessa päätyy. Tällöin ristiseiskaa pelatessa pelataan toisaalta ristiseiska-nimistä korttipeliä, mutta myös ristiseiskan pelaaminen -nimistä metapeliä, joka on syntynyt toistuvien ristiseiskavääntöjen myötä. Vastaavia metapelejä löytyy vähän jokaisesta videopeliskenestä – esimerkiksi sukupolvikokemusmainen Dark Souls -videopeli (2011) on täynnä toisten pelaajien tekemiä metapelillisiä viestejä (kuilun edessä lukee ”Try jumping” jne.).
Metapeli on siis peli pelistä. Metataide, näin ollen, on taidetta taiteesta – eli taidetta, jonka taiteellisuus perustuu taiteen omien sääntöjen rikkomiseen tai kyseenalaistamiseen. Metaversumi on universumi universumista (tai jotakin sellaista).
Metadata, tutkimusdatanhallinnan näkökulmasta tärkein meta-alkuinen termi, on näin ollen dataa datasta eli tietoa tiedosta. Siis mitä häh?
Hillopurkkiesimerkki

Metadatassa vaikeinta on sen nimi. Eikä sekään ole enää niin vaikea. Vaikeampaa taitaa olla termin verbalisoiminen yleisymmärrettävällä tavalla. Siispä turvaudun vakiopoppaskonstiini, esimerkkiin.
Oletetaan, että olen kovin halukas ostamaan salmiakki-mustaherukka-ananashilloa (moista hirvitystä ei toivottavasti ole olemassakaan). Menen läheiseen kauppaan ja etsin opasteista kyltin, jossa lukee HILLOT. Oikealta hyllyltä etsin kaipaamani hillohirvityksen. Luen etiketistä hillon ainesosista, tuotantomaasta sekä annosteluohjeesta (ruokalusikallinen kerrallaan suoraan biojätteeseen). Ostaessani hillopurkkia, tiskillä luetaan etiketistä viivakoodi, joka kertoo numerosarjan, jolla kassajärjestelmä osaa kertoa tuotteen nimen hintoineen (joukko makunystyröitä ja yksi sielu).
Tässä esimerkissä tulee esiin kolmea erilaista metadataa, joista kaikki ovat itsessään tärkeitä. Ensimmäinen on sijantitieto: opaste osoittaa hyllyn, jolla kaikki kaupan hillopurkit (ja näiden joukossa hirvitykseni) sijaitsevat. Toinen on kuvaava metadata: etiketistä luen kaiken tämän hillon maailmaan ilmaantumisen kannalta tärkeän. Kolmas on tunnistavaa eli identifioivaa metadataa: viivakoodi yksilöi (joskin vain tiettyyn rajaan saakka) hillopurkkini muista hillopurkeista ja tuotteista ylipäänsä.
Mikään metadatasta ei korvaa dataa itseään. Eli tieto siitä, mitä kaikkea hilloon on laitettu, missä se on tehty ja mikä on sen viimeinen käyttöpäivä, ei itsestään kerro miltä hillo maistuu. Se saattaa auttaa, toki: kun tiedän, että hirvitykseni ainesosiin sisältyy painajaismainen yhdistelmä aineksia, osaan varautua syömiskokemukseen pukluämpärillä. Toisaalta, jos kuvailisin tekstiksi sisäiset tuntemukseni tuon hillon syömisestä, sen voisi katsoa olevan metadataa kokemuksestani hillon mausta sekä hillon syömisestä. (Sivuhuomio: hetkinen, eikös tämä tarkoita sitä, että kaikki kirjallisuus on vain elämän metadataa? Uugh… näin syviin vesiin ei ehkä parane lähteä kahlaamaan sivuhuomiossa.)
Ei vain ihmisiä varten
Hillopurkkiesimerkissäni metadata on analogista – kylttejä kaupassa, hillopurkin etikettiin painettuja tietoja – mutta datanhallinnassa metadata, kuten data jota se kuvailee, on digitaalista. Näin ollen samanlaiset keinot kuvailla tietoa eivät passaa. Kun hillopurkin kylkeen kirjoitetaan valmistusmaa ja ainesosat, valmistaja voi lähteä oletuksesta, että etikettiä lukee ihminen, joka ymmärtää luettua sanaa. Tietokoneet eivät kuitenkaan toimi näin, vaan tietokone ymmärtää asiat toisella tavalla, kielioppia seurailevan verbaalisen ilmaisemisen sijaan ykkösinä ja nollina.
Tätä ihmis- ja koneluettavuuden eroa voi havainnollistaa ihmiskokeella, jota kuka vain voi kokeilla juuri nyt. Mene selaimellasi Helka-tietokantaan ja hae kirjaston kokoelmista mitä tahansa kirjaa. Avaa etsimäsi kirjan tiedot klikkaamalla kirjan nimeä hakulistasta. Rullaa sivua himan alaspäin ja klikkaa kuvassa olevaa painiketta.
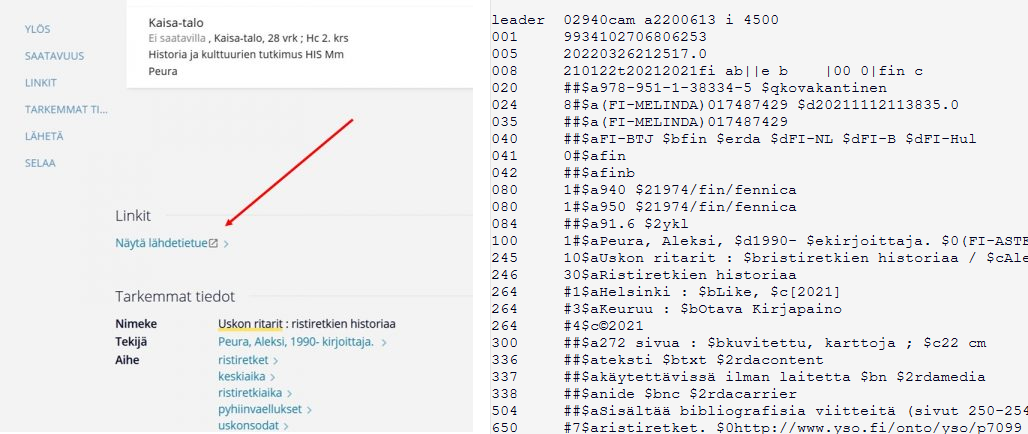
Jos et ole työskennellyt kirjastossa ja joutunut/päässyt tekemisiin RDA-kuvailun ja MARC-formaatin kanssa, et luultavasti ymmärrä paljoakaan näkemästäsi. Siinä sinulla kuitenkin on koneluettavaa metadataa, joka on ilmoitettu ihmisluettavimmin viimeisintä klikkausta edeltävällä sivulla – minkä niminen kirja on kyseessä, kuka sen on kirjoittanut, kuka julkaissut, minkä kokoinen nide on ja niin edelleen. Tiedot ovat samat, muoto toinen.
Kone- ja ihmisluettavuus kulkevat siis käsi kädessä. Jos tietokone osaa lukea metadataa, se osaa välittää sen ihmiskäyttäjilleen. Jos ihmiskäyttäjät saavuttavat metadatan, he pääsevät tarvitsemansa tiedon äärelle – ja samalla tiedontuottaja saa tuotokselleen lisää käyttäjiä. Hyvä, selkeä mutta kattava ja koneluettava metadata on näin ollen kaikkien osapuolten etujen mukaista.
…kai me tähän mustaherukkaakin laitettiin
Tutkijan näkökulmasta oman tutkimuksen ja sen datan näkyvyys on ehdottomasti hienoa, mutta saattaa tuntua tutkimusta tehtäessä painajaismaisen turhauttavalta: tässä minulla on tätä dataa, jota käsittelemällä tutkimustulokseni löytyvät, ja haluan vain tehdä tutkimustani – miksi siis käyttäisin aikaani kirjoittamalla auki jokaisen datan perustiedot? Kyllä, tämäkin haastattelu on tehty minun toimestani, Suomessa ja äänitiedosto kestää 33 minuuttia ja 51 sekuntia – so what, miksei tätä voi vain tehdä lopuksi?
Hyvä nyrkkisääntö metadatan tekemiseen eli kuvailuun on, että se on sitä parempaa, mitä nopeammin datan syntymisen jälkeen se on muotoiltu – ja mitä parempaa metadata on, sitä luultavammin se päätyy löydetyksi ja ymmärretyksi muiden toimesta. Voitko olla varma, että kuukausien tai vuosien päästä ymmärrät itsekään tekemäsi datan yhtä hyvin kuin juuri nyt, välittömästi datan syntymisen jälkeen? Jos olet hyödyntänyt erilaisia muuttujia, muistatko ne varmasti myöhemmin? Entä jos sinulla tulee kuukausien tai vuosienkin tauko tutkimuksen tekemisestä, voitko olla silloinkin täydellisen varma siitä, että ymmärrät käyttämäsi lyhenteet ja muuttujien merkitykset? Omasta graduaineistostani löytyy mm. kehittämiäni lyhenteitä E.ink., Dae., BD ja man.para. Hieman harmaata massaani penkomalla sain suhteellisella varmuudella pääteltyä mitä ihmettä olen ajatellut näitä kirjoittaessani, mutta täydellisen varma en ole. (E.ink. luultavasti viittaa Espanjan inkvisitioon, ehkä englantilaiseen inkunaabeliin tai johonkin ihan muuhun.)
Hyvä nyrkkisääntö metadatan tekemiseen eli kuvailuun on, että se on sitä parempaa, mitä nopeammin datan syntymisen jälkeen se on muotoiltu – ja mitä parempaa metadata on, sitä luultavammin se päätyy löydetyksi ja ymmärretyksi muiden toimesta.
Jos et ole täydellisen, absoluuttisen, sataprosenttisen varma siitä, että tulet aina ja ikuisesti muistamaan jokaisen käyttämäsi lyhenteen tai muuttujan merkityksen, ne kannattaa kirjoittaa auki mahdollisimman pian. Pahimmillaan data muuttuu käyttökelvottomaksi, jos se on täynnä muuttujia ja arvoja, joiden merkityksestä ei ole tarkkaa tietoa.
Olen kuullut tapauksesta, jossa tutkimusprojektissa kerättiin suuri määrä valokuvia, mutta kun kuvia hankittiin, niistä ei kerätty metadataa. Lopputuloksena oli kymmenien tuhansien (!) valokuvien aineisto, johon kuuluvien kuvien alkuperä (oliko ne otettu itse vai haettu jostakin tietokannasta – jos niin, mistä? jne.), paikkatiedot (missä kuva on otettu?) sekä sisältö (mitä kuvassa on?) oli selvitettävä ja kirjoitettava auki kertarysäyksellä tutkimuksen lopuksi. Urakassa on täytynyt kulua kuukausia enkä jaksa uskoa, että se on ollut kovin inspiroivaa työtä… tai että syntynyt metadata olisi ollut kovin laadukasta tai hyödyllistä. Todellinen lose-lose-tilanne.
Palataanpa vielä hetkeksi (väsyneeseen?) hillopurkkiesimerkkiini: Mietitään, että hillo on valmista, se on purkitettu ja valmiina lähtemään kauppoihin myyntiin, mutta etiketit puuttuvat täysin. Kukaan ei ole pitänyt tarkkaa kirjaa siitä, mitä kaikkea hilloon on laitettu, kukaan ei ole tallentanut hillon tuottamispäivämäärää, ja niin edelleen. Hillo olisi valmiina, mutta jotakin pitäisi etiketissä kuitenkin olla, että sitä voidaan myydä – eiköhän sitten arvioida eli heitetä hatusta raaka-aineet ja muut tarvittavat tiedot! Kai me tähän mustaherukkaakin laitettiin, joo, mutta oliko se nyt suomalaista, espanjalaista vai bulgarialaista? Laitetaan, että EU:ssa tuotettuja marjoja, niin se on ihan riittävä, eikö niin? Oliko se maanantai vai tiistai kun tämä erä purkitettiin? Vai jo viime viikolla? Ja niin edelleen, ja niin edelleen.
Kelpaisiko tällainen ”jotain me sinne laitettiin” -hillo myyntiin? Tohtisiko kukaan maistaa sitä? Uskallan epäillä.
Metadatan tärkeys
Uskon, että kaikki tutkijat ymmärtävät hyvän metadatan tärkeyden, vaikka he eivät asiaa näillä sanoilla ilmaisisikaan. Silti tutkimusdatalle tehdään säännöllisesti heikkolaatuista metadataa. Tämän dilemman ratkaisemista ovat pohtineet minua paljon välkymmät ihmiset, mutta dilemma jatkaa olemassaoloaan – tämä teksti on oma vaatimaton panokseni probleeman ratkomiseen tai ainakin esiintuomiseen.
Metadatan tärkeyttä on vaikea yliarvioida, mutta yritetään: ilman kunnollista metadataa tieto ei löydä etsijäänsä, kirja lukijaansa tai tuote kuluttajaansa. Onko tämä yliampuvaa? Ehkä, mutta jos on, ei totisesti paljoa.
Kunpa sillä ei vain olisi niin vaikea nimi. Vaikka eihän se taida edes niin vaikea olla.
Humanisti datamaailmassa -kirjoitussarja: